

Your development teams are stepping on each other. Database changes that should take hours are taking weeks. One service’s performance problems are bringing down the entire platform. Sound familiar? This is the reality for many organizations as they try to scale their digital platforms with a shared, monolithic database.
The database-per-service pattern is a fundamental shift that gives each microservice its own dedicated database. It’s one of the most critical architectural decisions you’ll make, with profound implications for how fast your team can ship features, how resilient your system is, and how much operational complexity you’ll face.
In this guide, we’ll explore how the database-per-service pattern addresses the core data challenges in microservices architectures. We’ll cover everything from choosing the right implementation strategy and embracing polyglot persistence to advanced synchronization techniques using Change Data Capture (CDC) and the Saga pattern.
Understanding the Database-per-Service Pattern
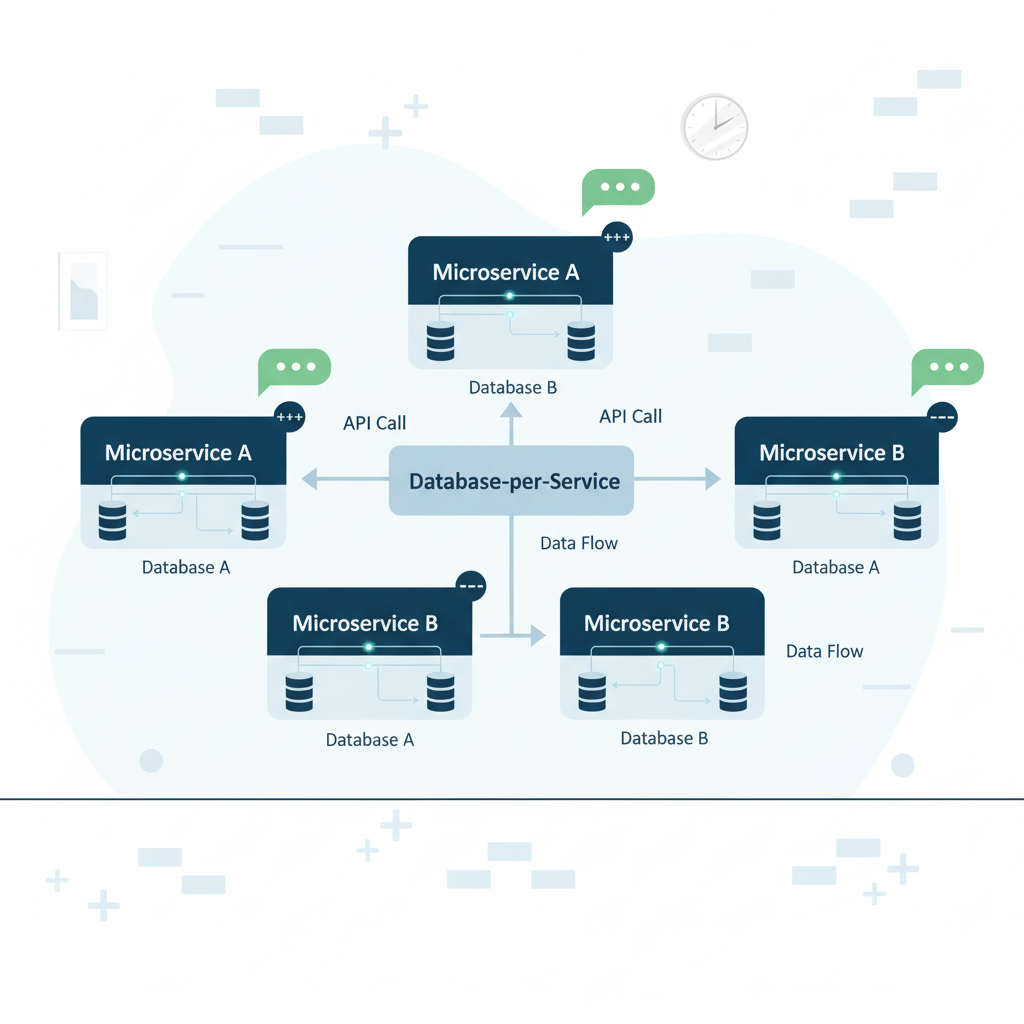
The database-per-service pattern is a microservices architecture approach where each microservice gets its own exclusive database. This promotes decentralized data management, ensuring that each service’s persistent data remains private and accessible only via its API.
Core Principles
Data Isolation: Each microservice completely owns its data. The service’s database is part of that service’s internal implementation and cannot be accessed directly by other services. This isolation prevents accidental data corruption and ensures that schema changes in one service don’t ripple across the entire system.
Service Autonomy: With dedicated databases, your services can evolve independently. Your teams can choose optimal database technologies, implement schema changes without coordination overhead, and deploy services on different schedules without data-layer dependencies.
Transaction Boundaries: A service’s transactions only involve its own database, eliminating the complex distributed transaction issues that plague shared database architectures.
Benefits Over Shared Database Approaches
Traditional shared databases create several critical problems that the database-per-service pattern eliminates:
Schema Evolution Complexity: In monolithic applications, schema changes can affect multiple components, making updates risky and requiring extensive coordination. With database-per-service, updating a schema is simpler because only one microservice is affected.
Performance Isolation: Shared databases suffer from the “noisy neighbor” problem, where one service’s heavy queries can impact performance for all services. Database-per-service ensures that each service’s performance characteristics are isolated.
Technology Lock-in: Shared databases force all services to use the same database technology, preventing your teams from choosing optimal solutions for their specific use cases.
Implementation Approaches: Choosing Your Strategy
The database-per-service pattern offers three primary implementation approaches. Each comes with different trade-offs between isolation, operational overhead, and resource utilization. Your choice will depend on your team’s size, compliance needs, performance requirements, and budget.
Private-tables-per-service
This is the most lightweight approach. Each service gets a dedicated set of tables within a shared database instance. While multiple services share the same database server, strict naming conventions and access controls ensure data isolation.
Benefits:
- Minimal Infrastructure Overhead: Less to set up and manage.
- Simplified Operations: Easier backup and disaster recovery for smaller teams.
- Lower Cost: Fewer database instances mean lower hosting costs.
Trade-offs:
- Limited Technology Diversity: All services must use the same database engine.
- Potential Performance Interference: One service’s heavy load can still impact others.
- Single Point of Failure: The shared database server can still bring down multiple services if it fails.
Best for: Small to medium-scale applications where operational simplicity and cost efficiency are more critical than absolute isolation. Think about this if your team is just starting with microservices.
Schema-per-service
Each service receives its own database schema within a shared database instance. This provides stronger logical separation than private tables while maintaining some operational efficiency.
Benefits:
- Clear Ownership: Stronger boundaries through schema isolation.
- Moderate Operational Overhead: Still easier to manage than separate servers.
- Better Security: Improved access controls at the schema level.
Trade-offs:
- Still Limited Technology: You’re still tied to a single database technology.
- Coordination Needed: Schema migrations might still require some coordination to avoid conflicts.
- Performance Impact: Performance can still be affected by other services on the same instance.
Best for: Organizations with strong database governance practices that need clear data ownership without the full infrastructure isolation. This is a good step up if private tables become too restrictive.
Database-server-per-service
Each service operates its own dedicated database server. This provides maximum isolation and technology freedom, representing the purest implementation of the database-per-service pattern.
Benefits:
- Complete Isolation: Full separation of performance, security, and operational concerns.
- Technology Freedom: Your teams can choose the optimal database technology for each service.
- Independent Scaling: Services can scale and be maintained independently.
Trade-offs:
- Highest Overhead: Significant infrastructure and operational costs.
- Complex Operations: More complex backup, monitoring, and disaster recovery procedures.
- Strong DevOps Required: Your team needs robust DevOps capabilities to manage this complexity.
Best for: Large-scale applications with high-throughput services that require maximum autonomy and performance isolation. This is the goal for many, but it’s a significant investment.
Decision Framework
Choose your approach based on these key factors:
Team Size and Expertise: Smaller teams often benefit from private-tables or schema-per-service to reduce operational burden. Larger, more mature teams with strong DevOps capabilities can handle database-server-per-service.
Performance Requirements: High-throughput services typically require database-server-per-service for optimal performance isolation.
Technology Diversity Needs: If different services genuinely benefit from different database technologies (relational vs. NoSQL vs. time-series), database-server-per-service is necessary.
Compliance and Security: Regulated industries may require physical database separation, making database-server-per-service mandatory.
Cost Implications: More isolation generally means higher infrastructure and operational costs. Balance the benefits against your budget.
Timeline Expectations: Moving to database-server-per-service is a longer, more complex journey than starting with private tables. Plan accordingly.
Embracing Polyglot Persistence
One of the most powerful aspects of the database-per-service pattern is that it enables polyglot persistence. This means using different database technologies, each optimized for a service’s specific data characteristics and access patterns. It’s about picking the right tool for the job.
Database Selection Criteria
When choosing a database for a service, consider these factors:
Data Structure Requirements:
- Relational databases (PostgreSQL, MySQL): Excel for complex queries and transactional integrity. Great for structured data with clear relationships.
- Document databases (MongoDB, DynamoDB): Suit flexible schemas and varied JSON data. Ideal when your data structure might change frequently.
- Key-value stores (Redis, DynamoDB): Optimize for high-performance caching and session management. Perfect for quick lookups.
- Graph databases (Neo4j, Amazon Neptune): Handle complex relationships and traversals. Think social networks or recommendation engines.
Consistency Requirements:
- ACID-compliant databases: Essential for financial transactions and critical business operations where data must be immediately consistent.
- Eventually consistent systems: Suitable for high-scale, read-heavy workloads where a slight delay in consistency is acceptable.
- In-memory stores: For real-time applications requiring microsecond response times.
Scalability Patterns:
- Horizontal scaling capabilities: For services expecting rapid growth.
- Read replica support: For read-heavy workloads.
- Automatic partitioning: For data distribution.
Real-World Implementation Examples
Consider an e-commerce platform:
User Service → PostgreSQL: Complex user relationships, preferences, and account history benefit from relational integrity and complex query capabilities. ACID properties ensure consistent account states during updates.
Product Catalogue → MongoDB: Product information varies significantly across categories, making document storage ideal. Flexible schemas accommodate diverse product attributes without rigid table structures.
Shopping Cart → Redis: High-performance requirements for cart operations and session management. In-memory storage provides microsecond response times for user interactions.
Order Processing → PostgreSQL: Financial transactions require ACID compliance and complex queries for order fulfillment, inventory management, and financial reporting.
Analytics Service → ClickHouse: Time-series data and analytical queries benefit from columnar storage optimized for aggregations and reporting.
Technology Decision Framework
To make these choices, ask your team:
- What are the primary data access patterns? (Is it read-heavy or write-heavy?)
- How complex are the relationships between data entities?
- What consistency guarantees does the business logic require?
- What are the expected scalability requirements?
- How critical is query flexibility versus performance optimization?
Implementation Strategy:
- Start with familiar technologies for non-critical services to build confidence.
- Introduce specialized databases gradually as your teams develop expertise.
- Establish clear data migration patterns for technology transitions.
- Create standardized monitoring and backup procedures across all technologies.
Team Skill Requirements: Embracing polyglot persistence means your team needs to develop expertise across multiple database technologies. This requires investment in training or hiring specialized talent.
Migration Complexity: Moving data between different database types can be complex. Plan for data transformation and migration tools.
Solving Cross-Service Data Challenges
One of the biggest pain points for CTOs moving to microservices is how to efficiently query and aggregate data that spans multiple services. You’ve broken up your monolith, but now getting a complete picture of a customer or an order feels like a scavenger hunt. This section explores three primary patterns for managing cross-service data access, each with its own business trade-offs.
API Composition Pattern
API composition involves orchestrating multiple service calls to gather distributed data, then combining the results at the application layer. Think of it as a “gateway” service that pulls information from several microservices to build a single response.
Benefits:
- Maintains Service Boundaries: Each service keeps its data private.
- Simple to Implement: Relatively straightforward for simple aggregations.
- No Additional Infrastructure: Doesn’t require new database instances or streaming platforms.
Trade-offs:
- Performance Issues: Multiple service calls can lead to higher latency, especially with many services.
- Complex Error Handling: If one service fails, how do you handle the partial response?
- Network Latency: Each hop adds to the overall response time.
Best for: Infrequent queries, dashboard aggregations, and user-facing applications where slight latency is acceptable. It’s a good starting point for simple cross-service data needs.
CQRS Implementation
Command Query Responsibility Segregation (CQRS) separates read and write models. This allows you to create optimized read models that aggregate data from multiple services specifically for querying.
Architecture Overview:
- Command Side: Services handle write operations in their dedicated databases.
- Event Publishing: Services emit domain events after successful writes.
- Read Model Construction: Dedicated read services consume these events to build optimized query models (often called “materialized views”).
- Query Processing: Read services handle all query operations using these pre-computed aggregations.
Implementation Benefits:
- Optimized Query Performance: Queries are fast because data is pre-aggregated and structured for reading.
- Reduced Cross-Service Communication: Read operations don’t need to call multiple services.
- Specialized Read Models: You can create different read models for different query patterns (e.g., one for customer dashboards, another for analytics).
Operational Considerations:
- Eventually Consistent: Read models may lag behind write operations, meaning data might not be immediately up-to-date.
- Additional Infrastructure: Requires event streaming platforms (like Kafka) and dedicated read model databases.
- Increased Complexity: Managing multiple data representations adds complexity.
Best for: Applications with complex reporting requirements, high query loads, or a need for specialized search capabilities. This is a more advanced pattern for when API composition isn’t enough.
Event-Driven Data Aggregation
This approach builds materialized views by consuming events from multiple services, creating eventually consistent but highly performant query capabilities. It’s often used as the underlying mechanism for CQRS read models.
Streaming Architecture:
- Apache Kafka: Often used as the central event streaming platform.
- Event Consumers: Services that listen to events and build aggregated views.
- Materialized Views: Precomputed aggregations stored in read-optimized formats (e.g., a NoSQL database).
Performance Characteristics:
- Sub-millisecond Query Response Times: For aggregated data.
- Horizontal Scalability: Through event partitioning.
- Resilience: Through event replay capabilities.
Implementation Complexity:
- Event Schema Evolution: Managing changes to event schemas and ensuring compatibility.
- Consumer Failure Handling: Designing robust systems to handle failed event processing.
- Eventual Consistency Management: Understanding and managing the implications of eventual consistency.
Cost Implications: Setting up and maintaining an event streaming platform like Kafka, along with the additional databases for materialized views, can be a significant infrastructure cost.
Team Skill Requirements: Your team will need expertise in event streaming, distributed systems, and potentially new database technologies for the materialized views.
Managing Data Synchronization with Change Data Capture
Maintaining data consistency across microservices while preserving service autonomy is a core challenge. Change Data Capture (CDC) is a powerful technique that captures changes in database systems and streams these changes as events. This enables real-time data synchronization without tight coupling between services.
The Outbox Pattern Foundation
The Outbox pattern provides the foundation for reliable event publishing in database-per-service architectures. This pattern ensures that database changes and event publishing occur within the same transaction, guaranteeing consistency.
Implementation Mechanics:
- Transactional Writes: Your service writes both business data and event records within a single database transaction.
- Outbox Table: A dedicated table stores these events alongside your business data.
- CDC Monitoring: A Change Data Capture system monitors this outbox table for new events.
- Event Streaming: The CDC system publishes captured events to message brokers (like Kafka).
Debezium Implementation
Debezium is a leading open-source CDC platform. It provides robust connectors for major database systems and integrates seamlessly with Apache Kafka. It’s a popular choice for building reliable event-driven architectures.
Architecture Components:
- Kafka Connect: A distributed streaming platform that runs Debezium connectors.
- Debezium Connectors: Database-specific components that monitor transaction logs (e.g., PostgreSQL’s WAL, MySQL’s binlog).
- Apache Kafka: The event streaming backbone for reliable message delivery.
Event Transformation: Debezium’s Outbox Event Router automatically transforms database change events into business domain events, routing them to appropriate Kafka topics based on event metadata.
Event Streaming Architecture
Topic Strategy:
- Domain-based Topics: Events grouped by business domain (e.g.,
orders,customers,inventory). - Service-based Topics: Events grouped by the originating service.
- Event-type Topics: Events grouped by action type (e.g.,
OrderCreated,ProductUpdated).
Benefits of CDC Implementation:
- Guaranteed Delivery: Events are published reliably through database transaction guarantees.
- Ordered Processing: Events maintain order through Kafka partition keys.
- Replay Capability: The event history enables system recovery and debugging.
- Loose Coupling: Services remain decoupled while maintaining data consistency.
Operational Considerations:
- Schema Evolution: Event schema changes require careful versioning and compatibility planning.
- Consumer Lag Monitoring: Track processing delays and implement alerting.
- Dead Letter Handling: Implement patterns for handling failed event processing.
Cost Implications: Implementing CDC with Debezium and Kafka involves setting up and maintaining a distributed streaming platform, which adds to infrastructure and operational costs.
Team Skill Requirements: Your team will need expertise in Kafka, Debezium, and event-driven architecture patterns.
Transaction Management: The Saga Pattern
Traditional ACID transactions don’t work across microservices with separate databases. This is a critical challenge for business processes that span multiple services. The Saga pattern provides a solution by implementing distributed transactions as a series of local transactions, each with compensating actions to handle failures.
Why Distributed Transactions Fail
Two-Phase Commit Problems:
- Performance Impact: Synchronous coordination creates significant latency.
- Availability Concerns: System availability is limited by the slowest participating service.
- Deadlock Potential: Cross-service locks can create complex deadlock scenarios.
- Scalability Limits: Coordination overhead grows exponentially with the number of participants.
CAP Theorem Implications: In distributed systems, you must choose between consistency and availability during network partitions. Microservices architectures typically prioritize availability, making traditional ACID guarantees impractical across service boundaries.
Choreography-based Sagas
In choreography-based sagas, services coordinate through event exchanges without a central coordinator. Each service listens for events and decides what actions to take next. It’s like a dance where each dancer knows their part and reacts to others.
Event Flow Example (Order Processing):
OrderCreated → PaymentProcessing → PaymentCompleted →
InventoryReservation → InventoryReserved → ShippingArranged → OrderConfirmedBenefits:
- Service Autonomy: Each service maintains its own business logic and decision-making.
- Loose Coupling: Services only need to understand relevant events, not implementation details of other services.
- Scalability: No central coordinator bottleneck.
Trade-offs:
- Complex Flow Tracking: Difficult to monitor overall transaction progress, especially for long-running sagas.
- Cyclic Dependencies: Event chains can become circular without careful design.
- Error Handling Complexity: Failure scenarios require comprehensive compensation logic across multiple services.
Best for: Simpler, shorter sagas where the flow is well-defined and unlikely to change frequently.
Orchestration-based Sagas
Orchestration uses a central coordinator (a “saga orchestrator”) to manage the entire transaction flow. This orchestrator explicitly calls each service and handles compensation if something goes wrong. It’s like a conductor leading an orchestra.
Benefits:
- Centralized Control: Easy to understand and monitor the transaction flow.
- Clear Error Handling: Centralized compensation logic and failure management.
- Transaction Visibility: A single place to track overall saga progress.
Trade-offs:
- Service Coupling: The orchestrator must understand all participating service APIs, creating a degree of coupling.
- Single Point of Failure: The orchestrator’s availability affects all transactions it manages.
- Scalability Constraints: Central coordination can become a bottleneck for very high-volume transactions.
Best for: Complex, long-running business processes where clear visibility and control over the transaction flow are crucial.
Compensating Transactions
Compensating transactions provide the mechanism to “undo” completed steps when a saga fails. Unlike database rollbacks, compensations must handle business-level rollback scenarios. For example, if a payment is processed but inventory reservation fails, the compensation isn’t just deleting a record; it’s refunding the payment.
Compensation Design Principles:
Idempotency: Compensations must be safely retryable. Running the same compensation multiple times should have the same effect as running it once.
Semantic Correctness: Compensations should restore the business state, not just the data state.
Audit Trail: Maintain complete records of compensation actions for debugging and compliance.
Cost Implications: Implementing sagas adds complexity to your codebase and requires careful design and testing, which translates to development time and effort.
Team Skill Requirements: Your team needs a deep understanding of distributed systems, event-driven architecture, and careful business process modeling to design effective sagas and compensation logic.
Real-World Implementation: Lessons from the Field
Understanding how successful organizations have implemented the database-per-service pattern provides crucial insights for your own implementation journey. Let’s examine key case studies and extract practical lessons.
Netflix’s Polyglot Persistence Journey
Netflix operates one of the world’s largest microservices architectures, with over 1,000 services managing data for 230+ million subscribers globally.
Technology Choices by Service Domain:
User Profiles and Preferences: Cassandra for high-scale user data with eventual consistency requirements.
Content Metadata: Elasticsearch for complex search and discovery operations.
Viewing History and Analytics: Amazon S3 and Spark for massive-scale data processing.
Financial Transactions: MySQL for subscription billing with ACID compliance requirements.
Session Management: Redis for ultra-low latency user session tracking.
Key Lessons:
- Gradual Migration: Netflix migrated from monolithic Oracle systems over several years, not a “big bang” approach.
- Technology Diversity: Different data domains genuinely benefit from specialized database technologies.
- Operational Excellence: Success required significant investment in monitoring, backup, and disaster recovery across multiple database platforms.
Migration Strategies: The Strangler Fig Pattern
Organizations transitioning from monolithic databases to database-per-service architectures require systematic migration approaches that minimize risk and business disruption.
Strangler Fig Implementation: The Strangler Fig pattern gradually replaces monolithic database functionality by routing increasing portions of traffic to new microservices while the old system continues operating.
Phase 1: Shadow Implementation Read from both old and new systems, comparing results for consistency validation.
Phase 2: Write-Through Migration Write to the authoritative (monolith) system, and asynchronously update the microservice. Log failures but don’t fail the operation.
Phase 3: Traffic Migration Gradually shift read traffic to the new microservice using feature toggles.
Phase 4: Monolith Decommission After validation, remove monolithic database dependencies and clean up migration code.
Common Implementation Pitfalls
Data Consistency Assumptions: Teams often underestimate the complexity of eventual consistency. Design APIs and user experiences that gracefully handle temporary inconsistencies.
Over-Engineering Initial Implementations: Starting with database-server-per-service for all services often creates unnecessary operational overhead. Begin with private-tables or schema-per-service approaches.
Insufficient Monitoring and Observability: Distributed data systems require comprehensive monitoring. Implement distributed tracing, correlation IDs, and centralized logging from the beginning.
Neglecting Data Migration Tools: Build robust data migration and consistency checking tools early. These become critical during service decomposition and technology transitions.
Team Organization and Conway’s Law
Conway’s Law states that organizations design systems that mirror their communication structures. This principle has profound implications for database-per-service implementations.
Successful Team Structures:
Service Teams: Each microservice has a dedicated team responsible for database design, performance optimization, and operational maintenance.
Platform Teams: Centralized teams provide shared infrastructure for monitoring, backup, disaster recovery, and development tooling.
Data Engineering Teams: Specialized teams manage cross-service data flows, analytics pipelines, and compliance requirements.
Anti-patterns to Avoid:
- Centralized Database Teams: Traditional DBA teams often resist service-specific database choices, slowing innovation.
- Shared Service Ownership: Multiple teams managing the same service create coordination overhead and unclear accountability.
Best Practices and Decision Framework
Successfully implementing the database-per-service pattern requires careful consideration of when to apply the pattern, how to manage the transition, and what practices ensure long-term success.
When to Use Database-per-Service
Ideal Scenarios:
Service Autonomy Requirements: When your teams need to deploy, scale, and evolve services independently without coordination overhead.
Performance Isolation Needs: When services have significantly different performance characteristics or SLA requirements that shared databases cannot accommodate.
Technology Diversity Benefits: When different services would benefit from specialized database technologies (graph databases for recommendations, time-series databases for metrics, etc.).
Compliance and Security: When regulatory requirements mandate data isolation or when different services handle data with different sensitivity levels.
Team Scale and Expertise: When you have sufficient team size and database expertise to manage multiple database technologies effectively.
When to Avoid Database-per-Service
Cautionary Scenarios:
High Transaction Coupling: When business processes require strong consistency across multiple data domains, the complexity of distributed transactions may outweigh isolation benefits.
Small Team Constraints: When limited operational expertise makes managing multiple database technologies risky or unsustainable.
Simple Application Domains: When data relationships are straightforward and services are unlikely to need different database technologies.
Regulatory Simplicity: When compliance requirements are simpler with consolidated data storage and unified audit trails.
Security Considerations
Network Security:
- Implement service-to-service authentication and authorization.
- Use network segmentation to isolate database access.
- Deploy services in private subnets with controlled egress.
Data Encryption:
- Encrypt data at rest across all database instances.
- Use TLS for all inter-service database communications.
- Implement key rotation policies for encryption keys.
Access Control:
- Implement comprehensive audit logging for all data access.
- Maintain data lineage tracking across service boundaries.
- Design GDPR-compliant data deletion workflows.
Performance Optimization Strategies
Read Replicas and Caching: Use read replicas for better read performance and implement intelligent caching strategies with proper invalidation policies.
Connection Pooling: Configure appropriate connection pools for each service’s database connections to manage resource utilization effectively.
Cost Management Strategies
Right-sizing Database Instances:
- Monitor CPU, memory, and I/O utilization across services.
- Use auto-scaling for variable workloads.
- Consider serverless database options for infrequent access patterns.
Storage Optimization:
- Implement data archiving for historical records.
- Use compression for large text/JSON fields.
- Monitor storage growth trends and plan capacity.
Multi-tenancy Considerations:
- Evaluate shared database instances for low-traffic services.
- Implement tenant isolation within databases where appropriate.
- Balance isolation benefits against infrastructure costs.
Required Team Skills and Training
Database Administration:
- Multi-database platform expertise (PostgreSQL, MongoDB, Redis, etc.).
- Performance tuning and optimization across different technologies.
- Backup and disaster recovery procedures.
DevOps and Infrastructure:
- Container orchestration for database deployment.
- Infrastructure as code for database provisioning.
- Monitoring and alerting across multiple database platforms.
Application Development:
- Event-driven architecture patterns.
- Distributed transaction management (Saga pattern).
- API design for service-to-service communication.
Training Recommendations:
- Start with Familiar Technologies: Begin database-per-service implementation with known database platforms.
- Cross-train Teams: Ensure multiple team members understand each service’s database requirements.
- Establish Centres of Excellence: Create specialized teams for complex areas like event streaming and distributed transactions.
Future-Proofing Your Data Architecture
As your microservices architecture evolves, anticipating future challenges and opportunities ensures your database-per-service implementation remains scalable, maintainable, and adaptable to changing business needs.
Resilience Patterns
Circuit Breaker Implementation: Protect services from cascading failures when database connections fail through proper fallback mechanisms and graceful degradation strategies.
Fallback Strategies:
- Cached Data: Serve stale but valid data during database outages.
- Default Responses: Return sensible defaults for non-critical data.
- Graceful Degradation: Reduce functionality while maintaining core operations.
Disaster Recovery Architecture
Multi-Region Database Replication: Implement cross-region backup replication, point-in-time recovery capabilities, and automated recovery testing procedures.
Scaling Considerations
Horizontal Scaling Patterns:
- Read Replicas: Scale read operations independently from writes.
- Database Sharding: Distribute data across multiple database instances.
- Vertical Scaling: Increase compute resources for high-demand services with proper monitoring and auto-scaling policies.
Emerging Technologies Integration
Event Sourcing Evolution: Event sourcing provides a natural evolution path for database-per-service architectures by capturing all state changes as events, enabling complete state reconstruction and audit trails.
CRDT Integration: Conflict-free Replicated Data Types enable eventually consistent data synchronization without coordination, particularly useful for globally distributed systems.
Evolution Path Planning
Growing from Simple to Complex:
Phase 1: Start with private-tables-per-service for minimal operational overhead and clear data ownership boundaries.
Phase 2: Migrate to schema-per-service for stronger isolation and independent schema evolution.
Phase 3: Implement database-server-per-service for maximum isolation, polyglot persistence capabilities, and full operational independence.
Phase 4: Advanced patterns implementation including event sourcing for audit requirements and CQRS for complex query optimization.
Technology Adoption Strategy:
- Pilot Programs: Test new database technologies with non-critical services.
- Gradual Rollout: Expand successful technologies to additional services.
- Legacy Migration: Plan systematic migration from outdated technologies.
- Continuous Evaluation: Regularly assess technology choices against evolving requirements.
Success Metrics:
- Service Independence: Measure deployment frequency and coordination overhead.
- Performance Isolation: Track service-level SLA adherence.
- Developer Productivity: Monitor development cycle times and bug rates.
- Operational Efficiency: Measure infrastructure costs and operational overhead.
The database-per-service pattern represents a fundamental shift toward distributed, autonomous, and scalable data architecture. Success requires careful planning, gradual implementation, and continuous adaptation to emerging technologies and business requirements.
Frequently Asked Questions
Q: How do I handle data consistency across multiple microservices?
A: Data consistency in database-per-service architectures relies on eventual consistency patterns rather than immediate consistency. Implement the Saga pattern for distributed transactions, use Change Data Capture (CDC) for real-time data synchronization, and design your user interfaces to handle temporary inconsistencies gracefully. For critical business operations, consider keeping tightly coupled data within the same service boundary.
Q: What happens when one microservice database goes down?
A: Database failures should be isolated to individual services through proper circuit breaker patterns, fallback mechanisms, and graceful degradation strategies. Implement comprehensive monitoring, automated failover to read replicas, and cached data serving for non-critical operations. Design your services to continue operating with reduced functionality rather than complete failure when their database is unavailable.
Q: How do I query data that spans multiple microservices?
A: Cross-service queries require different patterns than traditional SQL joins. Use API composition for simple aggregations, implement CQRS with dedicated read models for complex queries, or build event-driven materialized views that pre-compute cross-service aggregations. Each approach trades consistency for performance and complexity, so choose based on your specific requirements.
Q: Should I use different databases for different services?
A: Polyglot persistence—using different database technologies for different services—can provide significant benefits when services have genuinely different data characteristics. Use relational databases for complex queries and transactions, document databases for flexible schemas, key-value stores for high-performance caching, and specialized databases for specific use cases like time-series or graph data. However, only introduce technology diversity if you have the operational expertise to manage multiple database platforms effectively.
Q: How can I prevent data inconsistency in microservices?
A: Design your system to embrace eventual consistency rather than fighting it. Implement robust event streaming with Change Data Capture, use idempotent operations that can be safely retried, implement comprehensive monitoring and alerting for data synchronization lag, and design business processes that can handle temporary inconsistencies. Most importantly, carefully define service boundaries to minimize the need for cross-service consistency.
This comprehensive guide to the database-per-service pattern provides the foundation for building scalable, maintainable microservices architectures. Success depends on thoughtful implementation, careful attention to operational concerns, and continuous adaptation as your system and team evolve.








