So, you’re looking at building Large Language Model (LLM) agents. With the recent increases in model capability at all sizes, and the feature-rich frameworks available (like LangChain, LlamaIndex, AutoGen, CrewAI, etc.), getting agents up and running is easier than ever.
However, there’s a significant jump from an initial functional prototype to a system that’s reliable, performs consistently well, and executes affordably when running in production.
It turns out, building the agent is the easy part. Making it truly performant is where the real challenges lie.
This article dives into that gap. We’ll look at the common hurdles faced when taking LLM agents into production and explore the essential tools and capabilities needed to overcome them.
Let’s get into it.
Why Agent Performance is Hard
Transitioning an LLM agent from a proof-of-concept to production-ready means tracking and addressing reliability, consistency, cost, and overall quality. Here are some of the key challenges:
- Hallucinations & Accuracy: hallucination poses a significant risk, especially if your application needs high precision. Ensuring factual consistency is crucial but surprisingly hard to guarantee consistently.
- Latency & Scalability: Users expect reasonably fast responses. Agents, particularly those running complex reasoning chains or calling multiple external tools, need to deliver results within acceptable timeframes, even when usage ramps up. A prototype that works fine with a few test requests might be too slow under real production load, or scaling it might become prohibitively expensive.
- Cost Management: LLMs are accessed via APIs charging per token (input and output). These costs can vary based on model, context size, caching and inference provider. You need ways to track costs granularly – maybe per user, per feature, or per agent run – but this often requires specific tooling.
- Prompt Brittleness & Engineering: Getting prompts right is more art than science sometimes. Crafting prompts that consistently guide the LLM to the desired behaviour is an iterative and often difficult process. Keeping these prompts effective as models update or requirements shift adds another layer of maintenance overhead.
- Context Window Limitations: LLMs can only “remember” a certain amount of information from the current interaction (their context window). In long conversations or complex tasks requiring information recall over many steps, they can forget earlier instructions or details, limiting their effectiveness. A long context window that might make an agent performant, will also make it more expensive to run.
- Complex Planning & Error Handling: Agents can struggle with tasks needing sophisticated multi-step planning. If an Agent can get each step right 90% of the time, if your process has 6 steps you’ll get a successful result only 60% of the time.
- Data Quality & Bias: The agent’s output is heavily influenced by its training data and any data you feed it at runtime (e.g., via Retrieval-Augmented Generation – RAG). If that data is poorly structured, incomplete, or biased, you risk getting inaccurate results.
- Security & Privacy: Integrating LLM agents brings security considerations. Think about potential data leaks, prompt injection attacks (where users trick the agent with malicious input), and the need to handle sensitive user data securely and comply with regulations like GDPR.
These aren’t just theoretical concerns. Companies like Acxiom, for example, faced difficulties debugging complex multi-agent setups and found they needed platforms like LangSmith to get the visibility required for optimisation and cost management. Research from Anthropic also suggests that simpler, more composable agent designs often prove more successful than highly complex, monolithic ones, highlighting that managing complexity itself is a major challenge. In Acxiom’s case, they were working with 60 LLM calls and over 200k tokens of context to answer a client request.
The challenges in building on top of LLMs are interconnected. Making a prompt more complex to improve accuracy will increase token count, cost, and latency. Simplifying logic to reduce latency might increase errors. Optimisation becomes a balancing act. This is where dedicated tooling becomes essential and you need to move beyond the basics of looking at logs and monitoring API call rates to true observability.
While monitoring tracks known metrics (errors, uptime), observability gives you the tools to understand why your system behaves the way it does, especially when things go wrong unexpectedly. Given the non-deterministic nature and potential for novel failure modes in LLMs, observability is critical for diagnosing issues that simple monitoring might miss.
Key Capabilities for Managing LLM Agents
Observability and evaluation platforms offer a suite of core capabilities designed to help you manage the performance, cost, and reliability of LLM agents.
Each platform has its own strengths and weaknesses, but they all offer variations on the same functionality:
- Monitoring & Tracing: This is foundational. It means capturing detailed records of everything your agent does – tracing the entire execution flow of a request, logging inputs, outputs, intermediate steps (like tool calls), latency for each step, cost, and any errors. Good platforms visualise these traces, making complex workflows easier to understand. For development teams, this detailed tracing is invaluable for debugging. You can quickly find latency bottlenecks, pinpoint where errors occurred in a chain, and see exactly how the agent produced a specific output, saving hours of diagnostic time.
- Cost Tracking & Analysis: With token-based pricing being common, keeping costs under control is vital. These platforms monitor token usage (prompts and completions), calculate costs per API call or session, and let you slice and dice cost data by user, feature, model, etc. Dashboards help spot trends, identify cost spikes, and find optimisation opportunities (like do you try using cheaper models for certain tasks).
- Experimentation & Evaluation: Improving agent performance requires systematic experimentation. Platforms facilitate this with features like A/B testing (comparing prompts, models, parameters side-by-side), automated quality metrics (like BLEU, ROUGE, BERTScore), workflows for collecting human feedback, using another LLM to evaluate outputs (“LLM-as-a-Judge”), and interactive “playgrounds” for quick prompt testing. These tools allow teams to take a data-driven approach, test hypotheses rigorously, validate changes before deploying them, measure performance against benchmarks, and continuously refine agent quality.
- Dataset Management: Good evaluation needs good data. Platforms often include tools to create, manage, and version datasets specifically for evaluating agent performance or even fine-tuning. You might import existing data, generate synthetic data, or – very usefully – create evaluation datasets directly from problematic production traces you identified via monitoring. This lets you build targeted tests based on real-world failures, ensuring your fixes address actual issues.
- Prompt Management (CMS): Prompts are central to agent behavior, but managing them can get messy. Many platforms now offer Prompt Management features, acting like a Content Management System (CMS) for your prompts. This typically includes a central registry, version control, collaboration features, and integrated testing. A key benefit for many teams is the ability to update and deploy prompt changes directly from the platform’s UI, without needing a full application code change or redeployment. This dramatically speeds up the iteration cycle for prompt engineering and can even allow non-technical domain experts to contribute to prompt refinement.
The real value comes from how these capabilities integrate. You might use monitoring to spot a pattern of poor responses, use those traces to create an evaluation dataset, test a new prompt against that dataset using experimentation tools, deploy the winning prompt via the prompt management UI, and then monitor its impact on performance and cost – all within the same platform. This integrated feedback loop is key for continuous improvement.
Of course, platforms vary. Some excel at deep tracing, others have prompt management UIs to allow non-developers to contribute, some come from a broader MLOps background with deep evaluation features, and others focus on simplicity and cost-effectiveness. This means you need to consider your specific needs when choosing.
5 Platforms For Agent Optimisation
Let’s look briefly at five platforms offering relevant observability and evaluation capabilities: Langsmith, Helicone, Weights & Biases (W&B) Weave, Langfuse, and PromptLayer.
Langsmith
Developed by the LangChain team, Langsmith integrates very tightly with the LangChain/LangGraph ecosystem. Its strengths are detailed tracing, debugging, evaluation, and monitoring, especially for complex chains built with LangChain (their core framework available in Python and JavaScript).
It’s a solid choice if your team is heavily invested in LangChain. It offers debugging traces, monitoring dashboards, cost tracking (per trace), a testing/evaluation framework with UI configuration, dataset management (including creation from traces), and a “Prompt Hub” for UI-based prompt management and deployment.
Integration is trivial for LangChain users. Pricing includes a free developer tier and paid plans ($39/user/mo Plus) suitable for small teams, with usage-based costs for extra traces.
Helicone
Helicone positions itself as an open-source observability platform focused on ease of use and cost management. Its standout features are super-simple integration (often just a one-line change via a proxy for your inference provider’s API), strong cost tracking (per user/model, caching), and flexibility (self-hosted or cloud).
It’s great if you prioritise rapid setup, tight cost control, or open-source. It monitors core metrics (latency, usage, cost, TTFT), supports prompt experiments/evaluations (including LLM-as-a-judge via UI), dataset curation, and UI-based prompt editing, versioning and deployment.
Integration via proxy is very fast; SDKs are also available. Pricing is attractive, with a generous free tier, a Pro plan ($20/seat/mo + add-ons for prompt/eval), and a cost-effective Team plan bundling features. The open-source self-hosting option offers maximum control.
Weights & Biases (W&B) Weave
Weave is the LLM component of the established W&B MLOps platform. It leverages W&B’s strengths in experiment tracking, model versioning, and dataset management, extending them to LLMs. It emphasises rigorous evaluation and reproducibility. Best suited for data science/ML teams, especially those already using W&B, needing sophisticated evaluation and MLOps integration.
It offers tracing linked to experiments, cost tracking, a powerful evaluation framework (pipelines, scorers, RAG eval), robust dataset management integrated with evaluation, and SDK/API integrations.
Pricing includes a limited free tier and a Pro plan ($50/mo+) with usage-based costs for data ingestion.
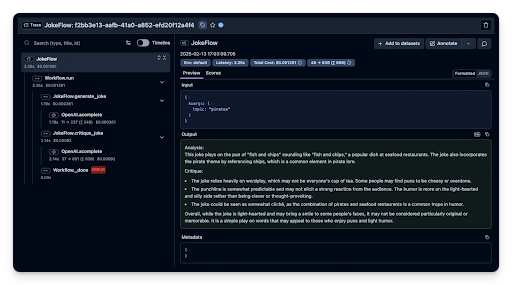
Langfuse
Langfuse is another prominent open-source LLM engineering platform (often seen as a Langsmith alternative) offering tracing, analytics, prompt management, and evaluation.
It appeals to teams wanting open-source flexibility, self-hosting, or broad framework support beyond LangChain.
It provides deep tracing (visualised), session/user tracking, cost tracking, extensive evaluation features (datasets from traces, custom scoring, annotation queues), dataset management, and broad SDK/integration support (including OpenTelemetry).
Its UI prompt management allows no-code deployment via labels (production/staging). Pricing is SME-friendly: a generous free cloud tier, affordable Core ($59/mo) and Pro cloud plans, and the FOSS self-hosting option.
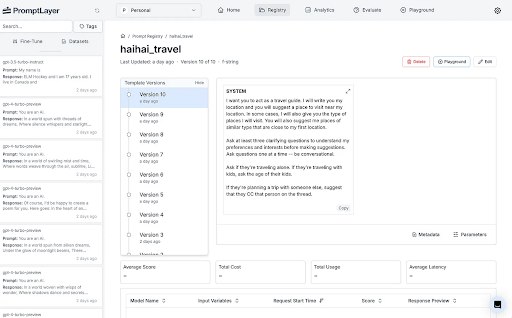
PromptLayer
PromptLayer focuses heavily on the prompt engineering lifecycle: management, versioning, testing, collaboration, and observability, with a strong emphasis on visual tooling (no-code prompt editor, visual workflow builder). Ideal for teams needing rapid prompt iteration, cross-functional collaboration (engineers, PMs, content specialists), and visual development.
It offers request logging, performance dashboards, cost tracking, prompt-centric experimentation (A/B testing, backtesting, human/AI grading), and SDK/API integrations.
Its core strength is the “Prompt Registry” – a visual CMS allowing no-code prompt editing, versioning, and importantly, UI-driven deployment decoupled from code releases. Pricing includes a limited free tier and a Pro plan ($50/user/mo) with a high request limit.
Comparing The Platforms
| Feature | Langsmith | Helicone | W&B Weave | Langfuse | PromptLayer |
|---|---|---|---|---|---|
| Ease of Integration | SDK | Proxy/SDK | SDK | Proxy/SDK | SDK |
| Monitoring Depth (Tracing) | High | Medium/High | High | High | Medium |
| Cost Tracking Granularity | Medium | High | High | High | High |
| Experimentation/Eval | High | Medium/High | Very High | Very High | High |
| Dataset Management | High | Medium | High | High | Medium |
| UI Prompt Mgmt (No-Code) | Yes | Yes | Unclear/Likely No | Yes | Yes (Core Strength) |
| Open Source Option | No | Yes | Yes | Yes | No |
| Key Strengths | LangChain integration; Balanced | Ease of integration; Cost control; Open Source | Robust evaluation; MLOps integration | Open Source; UI Prompt Mgmt; Balanced | UI Prompt Mgmt; Visual workflows |
Selecting the right platform involves weighing features, integration effort, cost, and how well it fits your team’s specific situation. Here are some key trade-offs you will want to consider:
- Open Source vs. Closed Source: Helicone and Langfuse offer open-source versions. This gives you potential cost savings via self-hosting, more data control, and avoids vendor lock-in. The trade-off is the technical overhead of setting up, maintaining, and scaling it yourself. Closed-source, managed cloud options (Langsmith, W&B Weave, PromptLayer) offer convenience and support but come with subscription fees and less control. You need to balance the desire for control/savings against operational resources.
- Ease of Integration: How quickly can you get value? Helicone’s proxy approach is near-instant. Langsmith is very easy if you’re already using LangChain. SDK-based integrations (common to most) require more code but offer flexibility. OpenTelemetry support provides standardisation but involves its own setup. Consider your team’s skills and how fast you need to get observability in place.
- Breadth vs. Depth: W&B Weave offers the broadest scope, embedding LLM observability within a full MLOps platform – powerful, but maybe overkill if you only need LLM tooling. PromptLayer goes deep on prompt management and visual workflows, perhaps with less emphasis on deep tracing than others. Langsmith and Langfuse offer a strong balance across tracing, evaluation, and prompt management. Helicone focuses tightly on core observability, cost, and ease of use. Identify your biggest pain point (debugging? prompt iteration speed? evaluation rigor? cost?) and align the platform’s focus accordingly.
- Pricing Models: Understand the costs. Per-user models are predictable by team size but can get pricey. Usage-based components (traces, requests, events, data ingestion) need careful estimation – W&B Weave’s ingestion cost, in particular, can be hard to predict. Free tiers are great for trials but often have limitations (users, retention) making them unsuitable for full production. Model your expected usage to compare the total cost of ownership (TCO).
- UI Prompt Management: The ability to manage and deploy prompts via a UI without code changes is a major accelerator for iteration and collaboration. Langfuse, PromptLayer, Helicone, and Langsmith provide this clearly. If rapid prompt iteration involving non-engineers is key, prioritise platforms strong in this area.
Ultimately, there’s no single “best” platform. The optimal choice depends heavily on your context: your main challenges, budget, team skills, existing tools (especially LangChain), and the strategic importance you place on features like open-source or UI-driven prompt deployment.
Get Your Agents Production-Ready
Developing and deploying LLM agents can feel like two different worlds: the initial build can feel straightforward, but achieving consistent, reliable, and cost-effective performance in production is a complex engineering challenge.
But that challenge can be navigated with the right platform. Find the one that fits your needs, integrate it into your process, and you can start optimising your Agents today.