



Nvidia holds roughly 90–93% of the AI accelerator market. You already know that. What the market share figure doesn’t tell you is why that number is so hard to shift — and why the companies best positioned to shift it have been trying for a decade and are still sitting in single digits.
The answer is a 20-year programme of vertical integration that methodically closed off every viable attack surface, one layer at a time. By the time most competitors identified the threat, Nvidia already owned the layer they needed to challenge it.
This article maps every layer Nvidia controls, explains the strategic logic behind each, and addresses the counterintuitive argument at the centre of Nvidia’s current position: its decision to wind down DGX Cloud was not a retreat. It was a deliberate move that strengthened its hold on the customers it actually needs. For the full picture of Nvidia’s AI hardware dominance, see our strategic overview of the Nvidia empire.
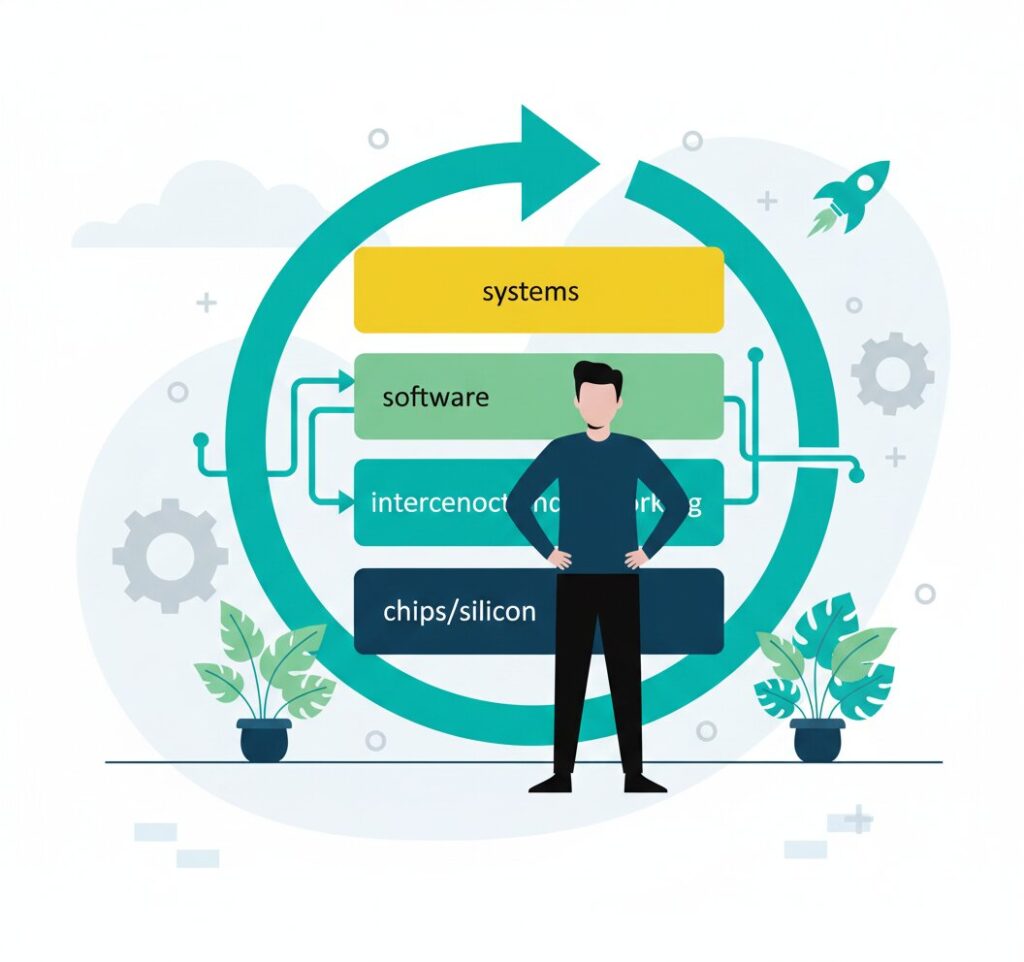
What layers of the AI stack does Nvidia actually control?
Nvidia’s dominance is not a single product advantage. It is the accumulation of control across six distinct infrastructure layers, each reinforcing the others.
Silicon. Nvidia designs its own GPU architecture — currently Blackwell, with Vera Rubin shipping into 2026 — manufactured exclusively through TSMC. The December 2025 Groq acquisition added a complementary inference-specific silicon layer: the Groq 3 LPU, built around massive on-chip SRAM for low-latency token generation at speeds GPU memory bandwidth simply cannot match.
Within-node interconnect. NVLink and NVSwitch connect GPUs within a single node at approximately 900 GB/s — roughly 7× faster than commodity PCIe 5.0. The NVL72 rack is the building block of every current Blackwell and Vera Rubin deployment.
Cross-node networking. In 2020, Nvidia acquired Mellanox Technologies for US$6.9 billion, picking up InfiniBand — the high-performance networking fabric that links NVLink clusters across an entire data centre. Before the acquisition, InfiniBand was neutral infrastructure any GPU cluster could use. Afterwards it was optimised for Nvidia workloads, turning a formerly neutral component into a proprietary advantage.
Software ecosystem. CUDA (launched 2006), NCCL, cuDNN, and cuBLAS form a software platform embedded into every major ML framework. PyTorch, TensorFlow, and JAX all treat CUDA as the primary execution target. Four million developers and 40,000 companies run inside this ecosystem.
Turnkey systems. DGX SuperPOD packages NVLink nodes, InfiniBand fabric, storage, and management software into a single validated reference architecture — “the entire technology stack, from computing to networking to software, as a single, cohesive system.”
Cloud (withdrawn). DGX Cloud launched in 2023 as a managed GPU-as-a-service offering and was wound down as a direct customer-facing product by 2026. Why that actually strengthened Nvidia’s position is its own section below.
The layered structure is the point. Each layer compounds switching costs. Breaking into any single layer is not enough — a competitor needs to displace multiple layers simultaneously. No one has managed it.
Why is CUDA the real moat — not the GPU hardware?
“The moat isn’t CUDA. The moat is everything built on CUDA.”
That captures something hardware-focused analysis consistently misses. CUDA is not a programming language. It is a 19-year-old platform — compilers, runtime libraries, debugging tools, math libraries, and domain-specific frameworks — that happens to require Nvidia hardware to run.
When AlexNet won the ImageNet competition in 2012 on two Nvidia GPUs running CUDA, it set the trajectory for the next decade. AI researchers trained on CUDA. Universities incorporated it into curricula. Companies prioritised CUDA expertise in hiring. Competitors fell behind not just in hardware but in the software ecosystem that determines what researchers reach for first.
The switching cost is a software problem, not a hardware problem. A developer migrating from CUDA to AMD ROCm doesn’t just change hardware — they rewrite CUDA kernels to HIP, replace cuDNN calls with MIOpen equivalents, and lose access to a community of solved problems. In compute-intensive workloads, CUDA typically outperforms ROCm by 10–30%. The hardware cost of switching is a one-time purchase. The software cost is an accumulating liability.
Every CUDA-dependent hire and every custom kernel your team writes adds to a switching cost that compounds invisibly. Nvidia’s Inception Programme, with more than 15,000 participating startups, entrenches this dependency at the emerging-company layer. For a deeper look, see our analysis of CUDA lock-in in depth — the software moat and real switching costs.
What is NCCL and why does it create vendor lock-in that most analysis misses?
There is a layer of Nvidia’s competitive position that gets far less attention than CUDA or GPU hardware, but creates arguably the most durable lock-in for production AI infrastructure: NCCL, the NVIDIA Collective Communications Library.
NCCL handles the all-reduce, broadcast, and scatter operations that distribute training across multiple GPUs and nodes — synchronising gradient updates after each forward and backward pass. At scale, collective communications performance is a primary determinant of total training throughput. NCCL exploits NVLink bandwidth within a node and InfiniBand bandwidth across nodes, and on a homogeneous Nvidia cluster it operates near theoretical maximum.
The lock-in is architectural, not contractual. NCCL and RCCL (AMD’s equivalent) are not interoperable. Introduce a non-Nvidia GPU into a multi-node cluster and you either exclude it from NCCL operations or force cross-vendor paths with degraded throughput. This is vendor homogeneity pressure: even if an AMD MI300X is cheaper per chip, inserting one creates a straggler problem — collective operations are constrained by the slowest device, dragging down the entire cluster’s throughput. The relevant unit of analysis is not the individual accelerator. It is the cluster.
The counter-move to watch is HetCCL — backed primarily by AMD — designed to enable efficient cross-vendor multi-GPU collective operations. In research settings it has demonstrated speedups of up to 1.48× over Nvidia-only NCCL training. If it reaches production-readiness, it removes the homogeneity pressure. For a full treatment, see our analysis of where the moat is currently weakest.
Why did Nvidia shut down DGX Cloud — and why did that actually strengthen its position?
Here is the counterintuitive read on DGX Cloud: shutting it down was not a failure. It was smart.
AWS, Azure, and GCP collectively represent Nvidia’s largest distribution channel — the primary route by which Nvidia hardware reaches enterprise customers at scale. Competing with them directly through DGX Cloud created channel conflict at precisely the moment when those customers were committing billions annually to Nvidia GPU capacity. That arrangement becomes untenable if Nvidia is simultaneously selling competing cloud services.
By stepping back, Nvidia preserved the hyperscaler relationships essential to the flywheel. AWS, Azure, and GCP all invest in their own accelerator programmes — Trainium, TPUs, Maia — yet all remain deeply dependent on Nvidia GPUs for leading-edge workloads. Preserving that dependency is worth more than cloud margins.
Nvidia’s advantage is silicon, systems, and software — not operating global data centre fleets. DGX SuperPOD infrastructure continues to reach enterprise customers through hyperscaler-managed deployments. The commercial relationship changed; the hardware and software stack did not. Like Microsoft open-sourcing .NET, the withdrawal removed a friction point and strengthened the ecosystem sustaining every other monetisation layer. DGX SuperPOD’s role in the global AI infrastructure arms race is covered in our analysis of DGX SuperPOD in the context of the global AI infrastructure arms race.
How does the Groq acquisition fit Nvidia’s competitive neutralisation playbook?
Nvidia doesn’t need to build every layer from scratch. It needs to ensure that no layer remains as an independent competitive threat once it has proven strategic importance.
The template was the Mellanox acquisition in 2020. InfiniBand was neutral networking technology used across many AI clusters. Nvidia acquired it for US$6.9 billion, integrated it into DGX SuperPOD, optimised it for NCCL workloads, and turned a neutral component into a proprietary advantage.
The Groq acquisition in December 2025 — approximately US$20 billion, Nvidia’s largest deal on record — repeats this blueprint precisely. Groq’s LPU architecture had demonstrated low-latency inference performance that GPU memory bandwidth cannot replicate. Rather than allow Groq to grow into a standalone inference platform enterprises could evaluate against Nvidia GPUs, Nvidia absorbed it. The Groq 3 LPX rack now sits beside Vera Rubin NVL72 racks in data centre deployments, positioned as a complementary inference accelerator — not a standalone product.
Jensen Huang stated this intent directly at GTC 2026: “An acquired company’s technology is absorbed into the platform as a core component rather than being operated as a stand-alone product.” Mellanox completed Nvidia’s networking layer. Groq completes the inference layer. The Groq deal as a strategic move is covered in our analysis of the Groq deal as the latest example of this neutralisation playbook.
Where is Nvidia’s moat starting to show cracks?
Nvidia’s position is not impenetrable. Three structural vulnerabilities are becoming visible as the inference economy scales.
TSMC supply constraint. Nvidia’s entire hardware roadmap depends on TSMC for advanced-node production, and GPU procurement lead times must be planned 18–24 months ahead. Some customers simply cannot get Nvidia hardware and are forced to deploy alternatives — inadvertently building non-CUDA expertise along the way.
LLMflation and inference cost pressure. Inference cost is decreasing by roughly 10× every year for equivalent performance — what Guido Appenzeller at a16z calls “LLMflation.” Midjourney reportedly saved 65% on inference costs by shifting from Nvidia GPUs to Google TPUs.
The reverse flywheel. As supply constraints push engineers toward ROCm or Google XLA, tooling and documentation for alternatives improve incrementally. Switching costs fall at the margin. If enough engineers accumulate non-CUDA production experience, the perceived risk of switching falls below the performance premium Nvidia commands.
These are real vulnerabilities — but not imminent threats. The more complete picture is in our analysis of where the moat is currently weakest.
What does Nvidia’s playbook mean for organisations building AI infrastructure now?
Understanding the structure of Nvidia’s moat is not academic. It is a prerequisite for making rational vendor decisions.
CUDA lock-in is software debt, not a hardware cost. Enterprises that build deeply on CUDA are accumulating a switching cost that compounds with every developer hired and every custom kernel written. That debt is manageable if you track it. It is dangerous if you do not.
Think in clusters, not accelerators. NCCL homogeneity pressure means GPU vendor decisions must be made at the cluster level. If you are evaluating whether a cheaper AMD MI300X can supplement an Nvidia training cluster, the relevant comparison is whole-cluster throughput under realistic NCCL workloads — not per-chip benchmarks.
Inference and training have different lock-in profiles. Training workloads are most deeply locked into CUDA and NVLink. Inference workloads are increasingly portable. Evaluate non-Nvidia options for inference first — that is where the financial case is clearest and the operational risk lowest.
The Groq acquisition removes a near-term hedge. If you were evaluating standalone Groq LPU infrastructure as an Nvidia-independent inference option, you need to reassess your vendor roadmap. The strategic independence that made Groq attractive as a hedge no longer exists in the same form.

Resistance to lock-in has a cost. The enterprises best positioned to resist Nvidia lock-in are investing now in ROCm expertise, framework-agnostic code patterns, and heterogeneous cluster architectures. It is expensive and complex. The payoff is on a 3–5 year horizon.
The right level of Nvidia dependency varies by company scale, workload profile, and risk appetite. A 50-person SaaS company running inference via API calls has almost no lock-in to manage. A 200-person HealthTech company running proprietary model training on owned infrastructure is accumulating CUDA debt whether it knows it or not. For a structured approach to these decisions, see our guide on what Nvidia’s playbook means for your vendor strategy. For a complete picture of how these forces connect, see our strategic overview of the Nvidia empire.
Frequently Asked Questions
How did Nvidia go from making gaming GPUs to controlling the entire AI stack?
Nvidia launched CUDA in 2006 to open gaming GPU hardware to general-purpose computation. AlexNet’s ImageNet win in 2012 established deep learning’s foundational association with the platform, and researcher training, curricula, and hiring priorities followed. Over the next decade Nvidia invested in CUDA tooling, acquired InfiniBand networking (Mellanox, 2020), and built DGX SuperPOD as a single-stack product. The gaming business funded the R&D. Vertical integration locked it in.
Why is it so difficult to switch away from Nvidia GPUs for AI training?
The barrier is the CUDA software ecosystem: 19 years of library development (cuDNN, cuBLAS, NCCL), framework-level optimisations in PyTorch, TensorFlow, and JAX, and developer familiarity built over years of production use. Moving to AMD ROCm requires rewriting model code, replacing library calls, and accepting months of reduced productivity. CUDA typically outperforms ROCm by 10–30% in compute-intensive workloads. The switching cost is denominated in engineering months, not hardware dollars.
What exactly did Nvidia acquire when it bought Groq?
Nvidia acquired Groq’s Language Processing Unit (LPU) — a chip architecture built around massive on-chip SRAM and deterministic compiler-scheduled execution that delivers low-latency token generation speeds unachievable by GPU memory bandwidth alone. The deal (approximately US$20 billion, non-exclusive licence plus broad hiring initiative) brought the engineering team as well as the technology. The Groq 3 LPX rack is paired with Vera Rubin NVL72 GPU racks, delivering up to 35× higher tokens per watt than Blackwell NVL72 alone.
What is the Mellanox acquisition and why does it matter for understanding Nvidia today?
In 2020, Nvidia acquired Mellanox Technologies for US$6.9 billion, obtaining InfiniBand — the high-performance networking fabric connecting GPU nodes across a data centre. InfiniBand was previously neutral infrastructure that favoured no GPU vendor. After the acquisition, Nvidia integrated it into DGX SuperPOD and optimised it for NCCL workloads, turning a neutral component into a proprietary advantage. Jensen Huang cited it as the strategic model for the Groq deal at GTC 2026.
Is it possible to build an AI data centre without relying on Nvidia?
Technically yes — AMD MI300X with ROCm, Google TPUs, or Amazon Trainium/Inferentia can each handle specific workloads. For multi-node training at scale the picture is more constrained: NCCL homogeneity pressure penalises mixed-vendor clusters, and InfiniBand is now optimised specifically for Nvidia workloads. A fully non-Nvidia AI data centre is achievable but significantly more complex and operationally expensive at scale.
What is the difference between NVLink and standard PCIe for AI workloads?
PCIe is the commodity standard connecting GPUs in a standard server. NVLink is Nvidia’s proprietary GPU-to-GPU interconnect delivering approximately 900 GB/s — roughly 7× the bandwidth of PCIe 5.0. GPU-to-GPU bandwidth determines how quickly gradient updates synchronise across GPUs within a node, translating directly to training throughput. Competing architectures using PCIe cannot match this within-node bandwidth.
What does DGX Cloud’s shutdown mean for enterprises that were using it?
DGX Cloud was wound down as a direct Nvidia customer-facing product. DGX SuperPOD infrastructure continues through hyperscaler partners (AWS, Azure, GCP). The hardware and software stack is unchanged — CUDA, TensorRT, NIM microservices, and the full DGX environment remain available through hyperscaler-managed deployments. Only the direct-from-Nvidia commercial relationship was discontinued.
How does NCCL create vendor lock-in at the cluster level?
NCCL handles collective communications — all-reduce, broadcast, scatter — coordinating gradient synchronisation across all GPUs during distributed training. It exploits NVLink within a node and InfiniBand across nodes. A non-Nvidia GPU forces cross-vendor communication paths with degraded throughput and straggler effects that make mixed-vendor training clusters economically unattractive at scale.
What is HetCCL and why does it threaten Nvidia’s networking moat?
HetCCL is a heterogeneous collective communications library backed primarily by AMD, designed to enable efficient multi-GPU collective operations across hardware from multiple vendors using RDMA. In research settings it has demonstrated speedups of up to 1.48× over Nvidia-only NCCL training. If it achieves production-readiness, it removes the homogeneity pressure that makes mixed-vendor training clusters economically unattractive — directly attacking the NCCL layer of Nvidia’s moat.
What is the “inference economy” and why does it create a challenge for Nvidia?
As AI moves from training into production deployment, inference serving becomes the primary optimisation target. McKinsey projects inference growing at 35% annually versus 22% for training through 2030, with inference accounting for 80–90% of total lifetime AI spending in production systems. Inference workloads are less dependent on NVLink and NCCL, more portable to alternative hardware, and LLMflation is making inference-specific alternatives financially compelling at an accelerating rate.
Is Nvidia facing antitrust scrutiny over its AI market dominance?
Yes. The DOJ antitrust division has opened investigations into Nvidia’s conduct in the AI chip market, issuing subpoenas regarding alleged unfair supply and pricing practices. Regulatory agencies in the UK, EU, France, South Korea, and China have also opened inquiries. The FTC announced in January 2026 it would examine “merger in disguise” arrangements, with specific scrutiny of the Groq deal’s non-exclusive licence structure. As of April 2026, no formal enforcement action has been concluded.









