

Traditional databases face a fundamental limitation: they store only current state, erasing the history of how that state evolved. When your organization needs comprehensive audit trails, temporal analysis, or the ability to reconstruct exactly how business events unfolded, traditional CRUD operations fall short. Event Sourcing emerges as a powerful architectural pattern that captures all changes to application state as immutable events in an append-only store, providing complete audit trails, temporal queries, and perfect system reconstruction capabilities that modern enterprises demand.
What is Event Sourcing and How Does It Differ from Traditional Database Approaches?
Event Sourcing stores business changes as immutable events rather than current state snapshots. Traditional databases update records in-place, losing historical context. Event Sourcing maintains complete change history, enabling time-travel debugging, comprehensive audit trails, and multiple read models from a single event stream.
Traditional CRUD Limitations
Traditional database systems operate by updating records in-place, fundamentally destroying the history of how data arrived at its current state. When you update a customer’s address from “123 Oak Street” to “456 Maple Avenue” in a traditional system, the previous address vanishes forever. This approach creates significant challenges for enterprises requiring detailed change tracking, regulatory compliance, or sophisticated analytics.
Your traditional database architecture suffers from several inherent limitations. Monolithic applications with tightly coupled data models make it difficult to evolve system requirements. The loss of historical context in operational databases prevents forensic analysis when business discrepancies arise. Most critically, you cannot reconstruct the sequence of business decisions that led to the current state, making audit compliance and temporal analysis nearly impossible.
Event-First Data Architecture
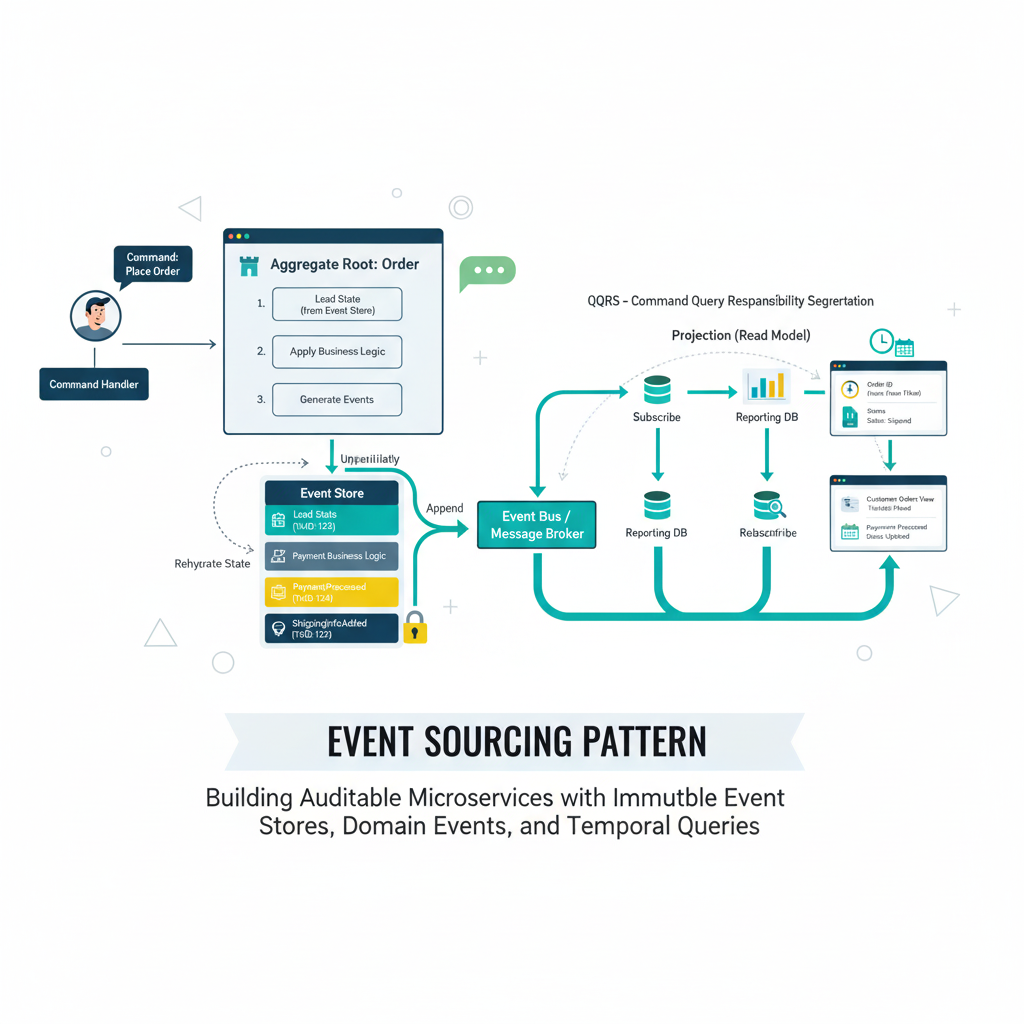
Event Sourcing fundamentally changes how applications capture and store data by focusing on recording every change as a sequential series of domain events. Instead of storing what the data looks like now, you store what happened to create that state. Each business action generates an immutable event like “CustomerAddressChanged”, “OrderPlaced”, or “PaymentProcessed” that gets appended to an event store, creating a permanent log of all changes.
This approach treats events as facts that have happened, capturing business intent through domain events rather than technical database changes. Events are appended to an immutable event store and preserve complete historical context of system changes. The event store becomes the single source of truth, containing every business decision and state transition that occurred throughout your system’s lifecycle.
Immutable Event Records
Events in an Event Sourcing system are immutable by design, meaning they cannot be modified once written. This immutability provides several critical advantages for enterprise systems. You gain complete audit trail capabilities with a full, immutable record of all system changes and the ability to reconstruct system state at any point in time.
The append-only nature of event stores enables “time travel” through application state by enabling reconstruction of system state at any historical moment. This capability proves invaluable for debugging complex business scenarios, understanding how edge cases developed, and providing the detailed historical analysis that regulatory frameworks often require.
What Are the Core Benefits of Event Sourcing for Enterprise Systems?
Event Sourcing provides complete audit trails for compliance, enables temporal queries for historical analysis, supports multiple read models through projections, facilitates debugging with event replay, and enhances system resilience through event-driven architecture. These benefits make it invaluable for financial services, healthcare, and regulated industries.
Compliance and Regulatory Benefits
Event Sourcing delivers unparalleled compliance capabilities for regulated industries. Financial systems represent the most common example – think of a bank ledger, which is essentially an event log of transactions. Every deposit, withdrawal, and transfer becomes an immutable event, creating the detailed, tamper-evident record keeping that regulatory frameworks demand.
Your compliance teams gain access to complete audit trails that satisfy the most stringent regulatory requirements. Event Sourcing provides immutable audit trails meeting regulatory requirements, temporal queries for historical reporting, and complete transaction reconstruction for forensic analysis. The append-only nature satisfies requirements for tamper-evident record keeping that many compliance frameworks explicitly require.
Business Intelligence Advantages
Event Sourcing transforms your approach to business intelligence by preserving complete historical context. Advanced analytics capabilities emerge naturally from the comprehensive event history, enabling sophisticated “time travel” analysis that traditional systems cannot provide. You can analyze business patterns over time, understand seasonal trends, and identify the specific sequence of events that led to both successful and problematic outcomes.
The pattern supports contextual AI and machine learning by providing comprehensive data preparation capabilities. Machine learning models can train on the complete history of business decisions and their outcomes, rather than just current state snapshots. This historical richness enables more sophisticated predictive modeling and business intelligence applications.
Technical Benefits for Development Teams
From a technical perspective, Event Sourcing offers exceptional system scalability and enables a loosely connected, event-driven approach. Your development teams gain powerful debugging capabilities through event replay, allowing them to reproduce exact historical scenarios in test environments. This capability dramatically improves the diagnosis and resolution of complex bugs.
Event Sourcing is particularly useful for debugging, auditing, and retroactively computing new insights from past events. When business stakeholders request new reports or analytics that weren’t originally planned, you can replay historical events to generate these insights without impacting production systems or requiring complex database migrations.
How Does Event Sourcing Integrate with CQRS and Microservices Architecture?
Event Sourcing naturally complements CQRS by providing events for the write side while projections create optimized read models. In microservices, events enable loose coupling between services, support eventual consistency, and facilitate distributed transaction management through patterns like Saga.
CQRS Integration Patterns
Command Query Responsibility Segregation (CQRS) separates the write side of an application from the read side, treating them as two different models. Commands modify (write) data, while queries read data, enabling independent scaling of read and write models. Event Sourcing provides the natural foundation for this separation.
In a CQRS architecture with Event Sourcing, write operations go through the event store, capturing business intent as domain events. The write side focuses on highly normalized, safe transactions that ensure business rules are enforced correctly. Any read model would pull from the events to construct its data, providing an immutable sequence of changes that can be projected into multiple optimized read models.
This separation enables significantly improved data reading performance in event-driven microservices. You can optimize reads and writes separately, maintaining highly normalized, safe transactions on the write side while creating completely denormalized, query-optimized tables on the read side.
Microservices Communication via Events
Event Sourcing decouples business logic from data models and enables modular, scalable application architectures that support microservices and event-driven designs. Events become the communication mechanism between services, enabling loose coupling while maintaining strong consistency within individual service boundaries.
Other services can subscribe to these events to update their own state, enabling event-driven patterns that naturally support microservices architecture. This approach eliminates the tight coupling that often plagues microservices implementations, where services need to make synchronous calls to multiple other services to complete business operations.
Events enable eventual consistency patterns across your distributed system while maintaining immediate consistency within individual aggregate boundaries. This balance provides the reliability guarantees your business requires while enabling the scalability and flexibility that microservices architecture promises.
Distributed Transaction Management
Event Sourcing facilitates distributed transaction management through patterns like Saga, which coordinates complex business processes across multiple microservices. Rather than requiring distributed transactions with two-phase commit protocols, you can model complex business processes as sequences of events that flow between services.
When one service publishes an event, other services can react by performing their part of the distributed business process and publishing their own events. This choreographed approach to distributed transactions proves more resilient than orchestrated approaches, as it eliminates single points of failure and enables services to recover independently.
The event-driven nature also supports compensation patterns naturally. If a business process needs to be rolled back, services can publish compensation events that reverse their previous actions, maintaining business consistency across the distributed system.
What Are Event Stores and How Do They Handle Concurrent Access?
Event stores are append-only databases optimized for storing sequential events with strong consistency guarantees. They handle concurrent writes through version-based conflict detection, where you specify expected version numbers when appending events. Conflicts reject the operation, ensuring data integrity.
Event Store Database Options
EventStore DB represents the most mature dedicated event store, providing built-in projections, clustering capabilities, automatic indexing on stream names and event types, and strong consistency guarantees. It offers specialized features designed specifically for event sourcing workloads, including efficient event replay, subscription capabilities, and optimized storage for append-only workloads.
KurrentDB provides event store capabilities with support for multiple programming languages and both cloud and on-premises deployment options. These dedicated event stores understand the unique requirements of event sourcing workloads and optimize their storage and query patterns accordingly.
For many organizations, PostgreSQL-based implementations offer a practical alternative using familiar technology. A single PostgreSQL events table with columns for stream_id, sequence_number, occurred_at, event_type, payload (JSONB), and metadata (JSONB) can provide robust event storage capabilities. Use composite indexes on (stream_id, sequence_number) for efficient querying and partial indexes on event_type for filtered projections.
Concurrency Control Strategies
Event stores handle concurrent access through version-based optimistic concurrency control. When appending events to an aggregate stream, you specify the expected version number. If another process has written events since you read the stream, the version won’t match and your write operation fails with a concurrency conflict error.
Common implementation patterns use database constraints to enforce uniqueness on (stream_id, sequence_number) combinations. When multiple processes attempt to append events to the same aggregate stream simultaneously, the database’s ACID properties ensure only one succeeds. The losing process receives a constraint violation error and can retry with the updated stream state.
This optimistic approach avoids the performance overhead of pessimistic locking while maintaining data integrity. Conflicts are detected at write time rather than preventing concurrent reads, enabling high read throughput while protecting against lost updates.
Consistency Guarantees
Event stores provide strong consistency guarantees within individual aggregate boundaries while supporting eventual consistency across aggregate boundaries. This design enables high-performance writes within aggregates while maintaining the flexibility needed for distributed system designs.
The approach emphasizes simplicity, flexibility, and maintaining clear boundaries between system components. Events are simple data objects containing business data and metadata, while store interfaces maintain minimal query() and append() methods that keep the architecture comprehensible and testable.
Atomic append operations ensure that event sequences remain consistent, preventing partial writes or corrupted event streams. These consistency guarantees provide the foundation that enables reliable event replay and projection generation, which are essential capabilities for event sourcing implementations.
How Do Projections Enable Multiple Read Models from Event Streams?
Projections transform event streams into optimized read models by processing events through projection handlers. Multiple projections can consume the same events to create different views for reporting, analytics, and user interfaces, supporting diverse query patterns without impacting core event store performance.
Projection Design Patterns
Events can be replayed to construct custom data models and allow building specialized views for different use cases. Projections decouple business logic from specific data representations and enable flexible data projections that serve different stakeholder needs from the same underlying event stream.
Each projection processes events differently, extracting the information relevant to its specific purpose. An e-commerce example illustrates this clearly: an order service stores events like “OrderPlaced”, “ItemAdded”, “PaymentProcessed” in the primary event store, but creates separate projections for user order history, product popularity rankings, and financial reporting that each optimize for their specific query patterns.
The read model pulls from the events to construct its data, providing an immutable sequence of changes that multiple projections can process independently. This independence means you can add new projections without impacting existing ones, and you can rebuild projections from historical events if requirements change.
Real-time vs. Batch Processing
Asynchronously processing events and creating optimized read models simplifies event-sourced application development while providing flexibility in how projections handle event streams. Real-time projections process events as they occur, providing up-to-date read models with minimal latency for operational use cases.
Batch processing approaches can handle high-volume event streams more efficiently, processing events in groups to optimize database write operations and reduce resource utilization. The choice between real-time and batch processing depends on your specific use case requirements and the acceptable latency for different types of queries.
CQRS allows optimizing reads and writes separately with highly normalized, safe transactions on the write side and completely denormalized, query-optimized tables on the read side. This separation enables you to choose the optimal processing approach for each projection based on its specific performance and latency requirements.
Read Model Optimization
Projections enable multiple read models from single event source, allowing you to optimize each read model for its specific query patterns and performance requirements. Different projections can use different database technologies, caching strategies, and data structures to optimize for their particular use cases.
Enhanced code clarity and better scalability emerge from more flexible system design that separates concerns between event capture and read model optimization. You can experiment with different read model designs without impacting the core event store or other projections, enabling iterative optimization based on actual usage patterns.
High scalability with clear separation of concerns creates an easy to understand and extend architecture. Teams can work independently on different projections, and you can scale read and write operations independently based on actual system usage patterns rather than theoretical performance models.
How Does Event Versioning Handle Schema Evolution Over Time?
Event versioning manages schema changes through versioned event definitions, upcasting transformations, and backward-compatible event handlers. Strategies include semantic versioning for events, transformation functions for legacy formats, and weak schema approaches using JSON for long-term system evolution.
Versioning Strategy Options
Event sourcing requires robust event versioning strategies and careful architectural design for systems needing detailed change tracking. The immutable nature of events means you cannot change historical events when business requirements evolve, so your versioning strategy must accommodate both current needs and future flexibility.
Framework-agnostic design with minimal abstractions ensures simple, testable architecture that can evolve over time. Events should be designed as simple data objects that can be extended and transformed as needed, avoiding tight coupling between event definitions and business logic implementations.
Semantic versioning provides a structured approach to managing event schema changes, enabling systems to understand which events are compatible and which require transformation. This approach supports gradual migration strategies where new event versions can be introduced while maintaining compatibility with existing event consumers.
Legacy Event Handling
Consumers of events need to handle idempotency as an event might be processed twice if re-reading the log, and they must also handle different versions of events as schemas evolve over time. Upcasting transformations enable legacy events to be processed by modern event handlers, ensuring that historical events remain usable as system requirements change.
Transformation functions can convert older event formats to current schemas, enabling unified processing logic while preserving historical data integrity. These functions must be carefully designed to maintain semantic equivalence between old and new event formats, ensuring that business logic remains consistent across event versions.
Backward compatibility maintenance requires careful consideration of how event schema changes impact existing projections and event consumers. Changes should be designed to extend rather than replace existing event structures whenever possible, minimizing the impact on downstream systems.
Schema Migration Patterns
JSON-based event payloads provide flexibility for schema evolution, enabling weak schema approaches that can accommodate gradual change without requiring complex migration procedures. This flexibility comes at the cost of type safety, so you must balance schema flexibility with the benefits of strong typing for your specific use case.
Migration strategies for existing event stores must consider both the technical aspects of schema transformation and the business impact of changing how historical events are interpreted. Gradual migration approaches often prove more practical than big-bang transformations, enabling you to validate changes incrementally.
The goal is maintaining the ability to replay historical events correctly while accommodating new business requirements that weren’t anticipated in the original event design. This balance requires thoughtful event design that anticipates future needs while avoiding over-engineering current implementations.
What Are the Performance Characteristics and Optimization Strategies?
Event Sourcing performance depends on event volume, projection complexity, and snapshot strategies. Optimization techniques include periodic snapshots every 100-500 events to reduce replay from minutes to milliseconds, projection optimization, event stream partitioning, and strategic caching for frequently accessed data.
Write vs. Read Performance Trade-offs
Event sourcing design pattern offers extremely scalable systems atomicity, particularly for write operations that benefit from the append-only nature of event stores. Write operations avoid the overhead of complex query optimization and lock contention that traditional databases face, enabling high-throughput write performance even under concurrent load.
For high-throughput systems, event logs like Kafka can be very scalable, providing the infrastructure needed to handle massive event volumes. The sequential nature of event writes aligns perfectly with the performance characteristics of modern storage systems, enabling excellent write performance across a wide range of deployment scenarios.
Read performance requires more sophisticated optimization through well-designed projections and caching strategies. Since events must be processed to generate read models, read performance depends heavily on projection design and the efficiency of event processing pipelines. This trade-off is fundamental to Event Sourcing and must be considered in your architecture decisions.
Snapshot Strategy Implementation
Snapshots are taken periodically for efficiency, with the source of truth remaining the sequence of events. Snapshots represent periodic captures of aggregate state that can significantly reduce the time required to rebuild current state from historical events.
Rebuilding state by replay can be slow if not managed properly, which is why snapshots become essential for maintaining acceptable performance. Implementing snapshots every 100-500 events for active aggregates can reduce replay time from minutes to milliseconds, depending on event complexity and reconstruction time requirements.
Snapshot strategies must be designed to maintain consistency with the event stream while providing the performance benefits needed for operational use. This includes handling concurrent access to snapshots during rebuild operations and ensuring that snapshot generation doesn’t impact write performance.
Scaling Event-Sourced Systems
High scalability with clear separation of concerns and easy to understand and extend architecture emerges from proper Event Sourcing implementation. Event stream partitioning enables parallel processing of events, allowing you to scale both event processing and projection generation across multiple processors or servers.
LinkedIn uses Kafka as a persistent log for activity data – not exactly event sourcing for a single entity, but conceptually storing events in a way that enables massive scale and high throughput processing. This approach demonstrates how event-based architectures can achieve the scale needed for enterprise systems.
Enhanced code clarity and better scalability with more flexible system design enables teams to optimize different aspects of the system independently. Write scaling can focus on event store performance, while read scaling can optimize projection generation and caching strategies based on actual usage patterns.
How to Implement GDPR Compliance in Event Sourcing Systems?
GDPR compliance in event sourcing requires handling the “right to be forgotten” despite immutable events. Solutions include crypto-erasure with user-specific encryption keys, redaction events marking data as deleted, anonymization techniques, and projection-level data filtering while maintaining audit integrity.
Right to be Forgotten Solutions
Event sourcing creates detailed, immutable records that can contain sensitive personal data with risks including regulatory violations, uncontrolled data access, and “purpose creep” where data collected for one purpose gets used inappropriately. The challenge lies in reconciling the immutable nature of events with the GDPR requirement to delete personal data upon request.
Despite event immutability, organizations can achieve compliance through redaction events that mask sensitive information, crypto-erasure, and anonymization of individual identifiers. Redaction events don’t delete historical events but mark them as containing data that should no longer be processed or displayed, maintaining audit integrity while respecting privacy rights.
The goal is to “remain maximally useful for analytics and AI without compromising trust” by implementing privacy protection mechanisms that preserve the business value of historical data while ensuring compliance with privacy regulations.
Crypto-Erasure Implementation
Crypto-erasure involves encrypting personal data within events using user-specific encryption keys, then destroying these keys when users request data deletion. For example, instead of storing “CustomerEmailChanged: [email protected]”, you store “CustomerEmailChanged: [encrypted_with_user_key_123]”. When John requests deletion, you destroy key_123, rendering his email unreadable while preserving the event structure and business context.
Privacy-conscious event design should practice data minimization, use pseudonymization techniques, tag event sensitivity levels, and separate sensitive data from core events. This separation enables targeted privacy controls without compromising the entire event stream when individual privacy requests are processed.
Implementation requires careful key management practices, including secure key storage, regular key rotation, and reliable key destruction procedures. The encryption approach must balance security requirements with the performance impact of encrypting and decrypting event data during normal processing operations.
Privacy-Preserving Projections
Implement role-based and purpose-based access controls, create policy-aware projections, and publish clear data product contracts and metadata to ensure that privacy controls extend beyond the event store to all derived data products. Projections can filter sensitive data based on current privacy settings, ensuring that deleted data doesn’t appear in read models even if the underlying encrypted events still exist.
Best practices include embedding privacy considerations in initial event design, documenting retention and erasure procedures, preferring controlled data products over raw event access, and maintaining comprehensive lineage tracking. This approach ensures that privacy controls remain effective as data flows through your event-driven architecture.
Policy-aware projections can dynamically filter data based on current privacy settings, user consent levels, and regulatory requirements. This capability enables fine-grained privacy controls that respect individual preferences while maintaining the business intelligence capabilities that Event Sourcing provides.
When Should You Choose Event Sourcing Over Traditional Approaches?
Choose Event Sourcing when you need comprehensive audit trails, temporal analysis, multiple read models from the same data, or complex business rules with regulatory requirements. Avoid it for simple CRUD applications, systems with minimal business logic, or when team expertise in event-driven patterns is limited.
Ideal Use Case Scenarios
Event Sourcing is best suited for systems needing detailed change tracking including financial services, healthcare systems, and real-time analytics platforms requiring detailed compliance and traceability. Services that need an audit trail such as stock trading, bank accounts, and ride-hailing trip status changes often use Event Sourcing to meet regulatory requirements and business analysis needs.
Real-world examples include shopping cart services that store every item added/removed event rather than current cart content, enabling sophisticated analysis of user behavior and abandoned cart recovery strategies. Banking transaction systems that need to trace every account balance change for regulatory reporting, and healthcare patient record systems that must maintain complete treatment history for legal compliance all benefit from Event Sourcing’s historical preservation capabilities.
The pattern proves particularly valuable when you need to support multiple read models from the same data, such as operational dashboards, regulatory reporting, business intelligence analytics, and customer-facing views that each require different data projections and query patterns.
Complexity and Cost Considerations
Event sourcing has a gap between initial simplicity and production use, requiring specialized event store infrastructure and expertise in event-driven architecture patterns. Increased system complexity requires robust event versioning strategies and should be applied strategically based on specific system requirements rather than as a default architectural choice.
The pattern emphasizes that while powerful, these approaches require careful architectural design and should be applied strategically based on specific system requirements. Teams need training in event modeling, projection design, and the unique debugging approaches that event-sourced systems require.
Frameworks like Emmett help reduce adoption barriers and focus on making event modeling intuitive and business-aligned, but the fundamental complexity of managing event schemas, projections, and eventual consistency remains a significant consideration in adoption decisions.
Migration Path Options
Event sourcing emphasizes making complex architectures more straightforward by capturing business processes through events, but migration from existing systems requires careful planning and execution. You can implement Event Sourcing incrementally, starting with specific domains or aggregates that benefit most from event capture.
Frameworks designed for “business-focused applications” like Emmett leverage TypeScript, Node.js, and event-driven principles to reduce the technical barriers to adoption. However, successful migration requires understanding both the technical implementation details and the business domain modeling that effective event sourcing requires.
Change Data Capture (CDC) can provide a bridge during migration, capturing database changes as events while you gradually refactor business logic to generate domain events directly. This hybrid approach enables gradual adoption while maintaining system stability during the transition period.
Frequently Asked Questions
Framework and Implementation FAQs
Q: Which Event Sourcing framework is best for Java enterprise applications?
Axon Framework is the leading choice for Java enterprise environments, offering comprehensive CQRS and Event Sourcing implementation with Spring Boot integration, built-in testing support, and enterprise-ready features including distributed command and event handling across multiple nodes. Alternatives include Akka Persistence for actor-based systems.
Q: How do you implement Event Sourcing with PostgreSQL and TypeScript?
Use PostgreSQL’s JSONB columns for event payloads with composite indexes on (stream_id, sequence_number) for efficient querying. Libraries like Emmett provide TypeScript-first approaches, or build custom implementations using PostgreSQL’s strong consistency guarantees and ACID properties for reliable event storage with proper error handling for concurrency conflicts.
Q: Can Apache Kafka serve as an Event Store for Event Sourcing?
While Kafka excels at event streaming, it lacks some Event Store features like complex queries and guaranteed ordering across partitions. It’s better suited as the event distribution layer, with dedicated event stores like EventStore DB or PostgreSQL handling persistence and replay capabilities for individual aggregates.
Architecture and Design FAQs
Q: How does Event Sourcing handle complex aggregates with multiple entities?
Use Aggregate Roots to maintain consistency boundaries, with child entities generating events through the root. Consider splitting large aggregates if they create concurrency bottlenecks, or use Process Managers (Sagas) to coordinate across multiple aggregates while maintaining consistency boundaries and avoiding distributed transaction complexity.
Q: What’s the difference between Event Sourcing and Change Data Capture?
Event Sourcing captures business intent through domain events like “OrderPlaced” or “PaymentProcessed”, while CDC captures technical database changes like “UPDATE orders SET status=’paid'”. Event Sourcing provides business semantics and supports temporal queries, whereas CDC primarily enables data replication and system integration.
Q: How do you test Event Sourced applications effectively?
Use behavior-driven testing with Given-When-Then patterns, testing command handlers with expected events, and projection testing with event fixtures. Event replay capabilities enable thorough integration testing by reproducing exact historical scenarios and validating projection behavior against known event sequences.
Performance and Scaling FAQs
Q: How do you handle Event Store backups and disaster recovery?
Implement continuous replication for Event Stores, regular snapshot backups, and geo-distributed replicas for disaster recovery. Test recovery procedures regularly, including projection rebuilding from backed-up events and cross-region failover capabilities to ensure business continuity with acceptable recovery time objectives.
Q: What’s the optimal snapshot frequency for Event Sourced aggregates?
Balance snapshot frequency against storage costs and replay performance. Start with snapshots every 100-500 events for active aggregates, monitoring replay times. Adjust based on aggregate complexity, event volume, and acceptable reconstruction times for your specific use case requirements and hardware capabilities.
Enterprise and Compliance FAQs
Q: How does Event Sourcing support financial services compliance requirements?
Event Sourcing provides immutable audit trails meeting regulatory requirements, temporal queries for historical reporting, and complete transaction reconstruction for forensic analysis. The append-only nature satisfies requirements for tamper-evident record keeping that financial regulators typically mandate for Sarbanes-Oxley and Basel III compliance.
Q: Can Event Sourcing systems comply with data retention policies?
Yes, through time-based event archival, projection expiration policies, and automated data lifecycle management. Archive old events to cold storage while maintaining projections for active queries, and implement retention policy enforcement at the projection level for operational efficiency while maintaining compliance.
Q: How do you handle event schema changes in production systems?
Implement versioned events with upcasting strategies, maintain backward compatibility through transformation functions, and use deployment strategies that support gradual rollout of schema changes. Test schema evolution thoroughly in staging environments with historical event replay before production deployment to avoid compatibility issues.
Q: Is Event Sourcing suitable for real-time applications?
Yes, when properly implemented with optimized projections, caching layers, and event streaming infrastructure. Real-time projections can provide sub-second latency for read operations, while write operations benefit from the append-only nature of event stores enabling high-throughput performance for real-time transaction processing.
Conclusion
Event Sourcing transforms how enterprise systems capture, store, and analyze business data by treating events as the fundamental building blocks of system state. This architectural pattern delivers comprehensive audit trails, temporal analysis capabilities, and flexible read model generation that traditional database approaches cannot match. For CTOs and Software Architects evaluating Event Sourcing, success depends on matching the pattern to appropriate use cases—particularly those requiring detailed compliance tracking, complex business rules, or sophisticated analytics capabilities.
Your next steps should focus on identifying specific domains within your organization that would benefit from event capture, evaluating team readiness for event-driven architecture patterns, and planning an incremental adoption strategy that minimizes risk while demonstrating value. Event Sourcing represents a significant architectural investment, but for the right use cases, it provides capabilities that can transform how your organization understands and leverages its business data.
Related Microservices Patterns
To fully understand Event Sourcing in the context of microservices architecture, explore these related patterns:
The Complete Guide to Microservices Design Patterns – Our comprehensive pillar guide covering all essential microservices patterns and their relationships.
CQRS Pattern: Command Query Responsibility Segregation – The natural companion to Event Sourcing for separating read and write operations.
Saga Pattern: Managing Distributed Transactions – Coordinate complex business processes across event-sourced microservices.
Database-per-Service Pattern: Data Isolation in Microservices – Understand data management strategies that complement Event Sourcing.








