In distributed systems, a single service failure can trigger a catastrophic chain reaction, bringing down entire applications. The Circuit Breaker pattern provides a critical defence mechanism, preventing cascading failures by detecting faults and failing fast. This architectural pattern has become essential for organisations building resilient microservices that must maintain availability even when dependencies fail.
What Is the Circuit Breaker Pattern and Why Do You Need It?
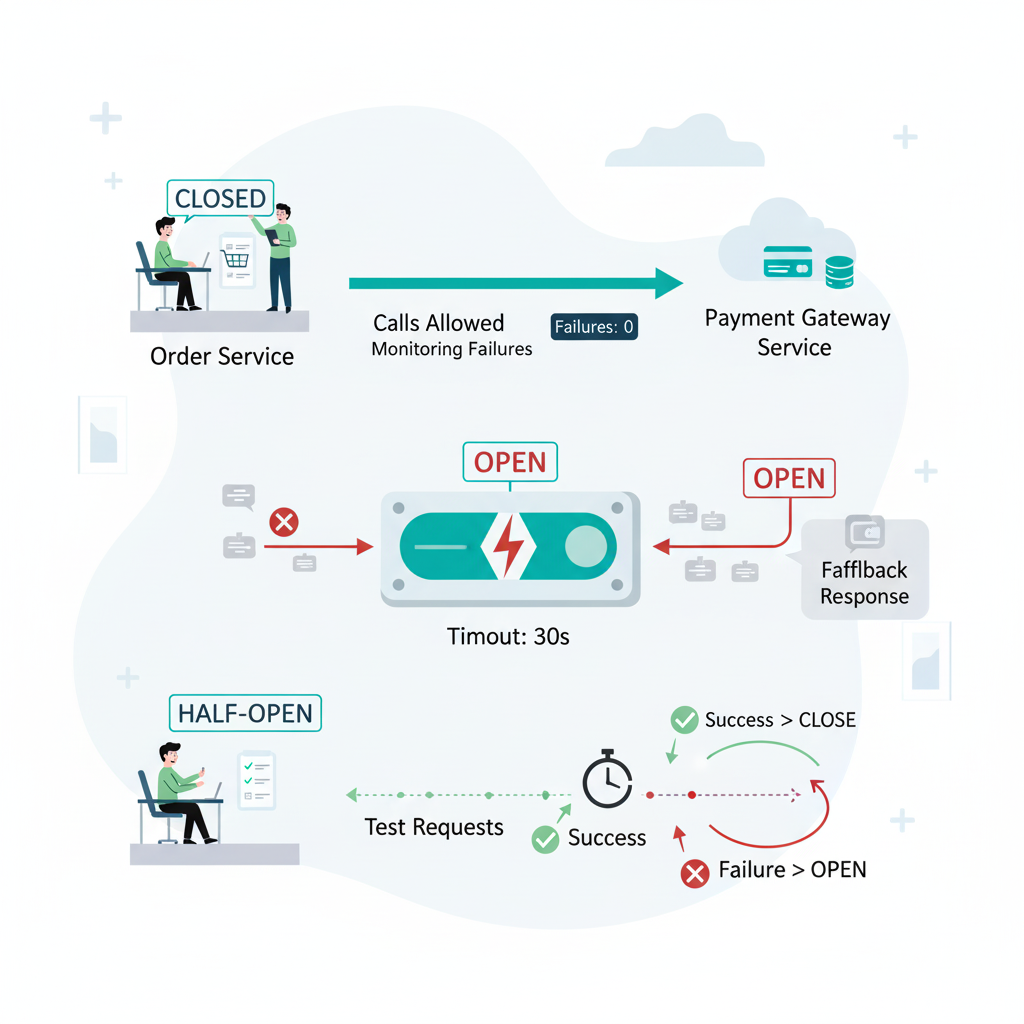
The Circuit Breaker pattern monitors service calls and temporarily blocks requests to failing services, preventing system overload and cascading failures. Named after electrical circuit breakers, it transitions between closed (allowing traffic), open (blocking traffic), and half-open (testing recovery) states based on failure thresholds, protecting both the calling service and the failing dependency.
In microservices architectures, services depend on multiple external components—databases, APIs, third-party services. When these dependencies fail, naive retry mechanisms can amplify problems, consuming resources and creating thundering herd effects. The Circuit Breaker pattern solves this by implementing intelligent failure detection and recovery strategies.
Consider Netflix’s implementation with Hystrix, which handles billions of requests daily across thousands of microservices. When a service experiences issues, circuit breakers prevent failure propagation, maintaining overall system availability whilst isolated components recover. This approach has enabled 99.99% availability despite constant partial failures across their infrastructure.
How Does Circuit Breaker State Management Work?
Circuit breakers operate through three distinct states: closed allows normal traffic flow whilst monitoring failure rates; open blocks all requests immediately returning errors or fallback responses; half-open permits limited test traffic to verify service recovery before fully reopening connections, creating a self-healing mechanism for distributed systems.
The closed state represents normal operation. Requests pass through to the service whilst the circuit breaker tracks success and failure metrics. When failure rates exceed configured thresholds—typically 50% over a sliding window—the circuit trips to the open state.
During the open state, all requests fail fast without attempting to contact the service. This prevents resource exhaustion and gives the failing service time to recover. After a configured timeout period, the circuit breaker transitions to half-open state.
The half-open state acts as a recovery test phase. A limited number of requests pass through to verify service health. If these succeed, the circuit closes and normal operation resumes. If they fail, the circuit returns to open state, extending the recovery period.
State transitions follow configurable rules based on your specific requirements. Common configurations include failure percentages (trip when 50% of requests fail), request volume thresholds (minimum 20 requests before evaluating), and timeout durations (wait 30 seconds before testing recovery).
When Should You Implement Circuit Breaker Pattern?
Implement Circuit Breaker pattern when services exhibit intermittent failures, external dependencies have variable reliability, cascading failure risks exist, resource exhaustion threatens system stability, or when you need graceful degradation capabilities to maintain partial functionality during outages whilst protecting critical system resources.
External API integrations present obvious candidates for circuit breakers. Third-party services have unpredictable reliability, and your system shouldn’t fail because a payment gateway or mapping service experiences issues. Circuit breakers enable graceful degradation, perhaps showing cached data or simplified functionality.
Database connections benefit from circuit breaker protection, particularly for read replicas or non-critical queries. When database servers become overloaded, circuit breakers prevent connection pool exhaustion and allow critical write operations to continue functioning.
Microservice-to-microservice communication requires careful circuit breaker implementation. Services calling recommendation engines, search services, or analytics platforms can continue operating with reduced functionality when these non-critical dependencies fail.
High-traffic scenarios demand circuit breakers to prevent thundering herd problems. When services restart after failures, circuit breakers gradually reintroduce traffic, preventing immediate re-failure from sudden load spikes.
Which Framework Should You Choose for Circuit Breaker Implementation?
Modern frameworks include Resilience4j for Java applications offering lightweight, functional programming approach; Polly for .NET environments with comprehensive resilience policies; Hystrix for legacy systems though now in maintenance mode; and service mesh solutions like Istio providing infrastructure-level circuit breaking without application code changes.
Resilience4j has emerged as the preferred Java solution, replacing Netflix’s Hystrix. It provides a functional programming model, integrates seamlessly with Spring Boot, and offers additional patterns like rate limiting and bulkheading. Configuration uses simple annotations and properties files.
For .NET applications, Polly delivers comprehensive resilience capabilities beyond circuit breaking. It supports retry policies, timeout handling, and fallback mechanisms through a fluent API. Integration with HttpClient and ASP.NET Core makes implementation straightforward.
Python developers can leverage py-breaker or implement custom solutions using decorators. These libraries provide basic circuit breaker functionality with minimal overhead, suitable for smaller services or specific use cases.
Service mesh implementations like Istio and Linkerd offer circuit breaking at the infrastructure level. This approach removes resilience logic from application code, providing consistent behaviour across all services regardless of implementation language.
How Do You Configure Circuit Breaker Thresholds and Timeouts?
Effective configuration requires analysing service behaviour patterns, setting failure thresholds between 50-70% for most services, implementing sliding windows of 10-20 seconds for evaluation, configuring reset timeouts matching typical recovery times, and continuously monitoring metrics to refine settings based on production behaviour patterns.
Failure thresholds determine when circuits trip. Setting thresholds too low causes unnecessary service disruptions, whilst high thresholds allow cascading failures. Most services operate well with 50% failure rates over 10-request windows, adjusting based on criticality and traffic patterns.
Timeout configurations balance recovery time against retry storms. Start with conservative values—30-60 seconds—then adjust based on observed recovery patterns. Services with quick recovery might use 10-second timeouts, whilst database connections might require several minutes.
Sliding window implementations provide more accurate failure detection than simple counters. Count-based windows evaluate the last N requests, whilst time-based windows consider requests within specific timeframes. Combining both approaches offers robust failure detection.
Half-open test traffic requires careful configuration. Allowing too many test requests risks overloading recovering services, whilst insufficient tests might not accurately assess health. Start with single request tests, increasing gradually for services with variable performance.
What Are the Common Circuit Breaker Pitfalls to Avoid?
Common pitfalls include setting uniform thresholds across all services, ignoring timeout configurations leading to premature trips, neglecting proper monitoring and alerting, implementing circuit breakers without fallback strategies, and failing to test circuit breaker behaviour under realistic failure conditions before production deployment.
Uniform configuration across services ignores individual characteristics. Payment services might require stricter thresholds than recommendation engines. Database connections need different timeout values than external APIs. Analyse each service’s behaviour and criticality to determine appropriate settings.
Missing fallback strategies leave users with error messages when circuits open. Implement meaningful degradation—return cached data, provide simplified functionality, or queue requests for later processing. Users prefer limited functionality over complete failure.
Insufficient monitoring blinds teams to circuit breaker behaviour. Track state transitions, failure rates, and recovery patterns. Alert on unusual patterns like frequent state changes or extended open states. Use dashboards to visualise circuit breaker health across services.
Testing failures often focus on complete service outages, ignoring partial failures and slow responses. Simulate realistic scenarios including intermittent failures, gradually degrading performance, and recovery patterns. Chaos engineering practices help validate circuit breaker effectiveness.
How Should You Monitor Circuit Breaker Performance?
Comprehensive monitoring tracks circuit state transitions, failure rates triggering trips, success rates during recovery, latency impacts from circuit breaker overhead, and business metrics showing user impact, using tools like Prometheus with Grafana dashboards or commercial APM solutions for real-time visibility.
State transition monitoring reveals circuit breaker effectiveness. Frequent transitions indicate unstable services or misconfigured thresholds. Extended open states suggest serious service issues requiring investigation. Successful recoveries validate timeout configurations.
Performance metrics quantify circuit breaker impact. Measure latency added by circuit breaker logic—typically microseconds but important for high-frequency trading or real-time systems. Track resource usage, particularly thread pool utilisation in threaded implementations.
Business metrics connect technical behaviour to user experience. Monitor feature availability, transaction success rates, and user journey completion. Circuit breakers should improve overall reliability even when individual services fail.
Alerting strategies balance noise against visibility. Alert on extended open states, unusual state transition patterns, and circuit breakers preventing critical business functions. Avoid alerting on every state change—some instability is normal in distributed systems.
What Integration Strategies Work Best with Existing Infrastructure?
Successful integration follows incremental adoption starting with non-critical services, implementing comprehensive logging before activation, establishing fallback mechanisms for graceful degradation, coordinating with load balancers and retry policies, and gradually expanding coverage based on observed benefits and operational experience.
Start with read-only operations or non-critical features. Recommendation services, search functionality, or analytics calls provide safe testing grounds. Monitor behaviour and refine configurations before protecting critical paths.
Coordinate circuit breakers with existing resilience mechanisms. Load balancers, retry policies, and timeout configurations must work together. Circuit breakers should activate before retry storms occur, and load balancers shouldn’t route traffic to circuits in open state.
Service mesh adoption provides infrastructure-level circuit breaking without modifying applications. This approach suits organisations with diverse technology stacks or legacy applications. However, it requires operational expertise and infrastructure investment.
API gateway integration centralises circuit breaker management. Gateways like Kong or Spring Cloud Gateway provide circuit breaking alongside rate limiting, authentication, and routing. This simplifies client implementations but creates a potential single point of failure.
Frequently Asked Questions
How do circuit breakers differ from retry logic?
Retry logic attempts operations multiple times hoping for success, potentially amplifying problems during outages. Circuit breakers detect failure patterns and stop attempts entirely, preventing resource exhaustion and allowing failing services time to recover.
What’s the performance overhead of circuit breakers?
Well-implemented circuit breakers add minimal overhead—typically microseconds per request. The performance benefit from preventing cascading failures far outweighs this cost. Memory usage remains constant regardless of traffic volume.
Should circuit breakers be implemented client-side or server-side?
Both approaches have merit. Client-side circuit breakers protect calling services from dependency failures. Server-side implementation protects services from overload. Many architectures implement both for defence in depth.
How do you test circuit breaker configurations?
Use chaos engineering tools to inject failures, latency, and partial outages. Test state transitions, fallback mechanisms, and recovery behaviour. Validate configurations under realistic load patterns before production deployment.
Can circuit breakers handle partial failures?
Yes, sophisticated implementations track errors by error type, endpoint, or other criteria. This enables partial circuit breaking—blocking failed operations whilst allowing healthy ones to continue.
What happens to in-flight requests when circuits open?
In-flight requests typically complete normally. New requests immediately receive errors or fallback responses. Some implementations allow graceful draining, completing existing requests whilst rejecting new ones.
How do circuit breakers work in serverless architectures?
Serverless platforms require stateless circuit breaker implementations using external state stores or probabilistic algorithms. Some platforms provide built-in circuit breaking capabilities through service quotas and throttling.
Should every service call use circuit breakers?
No, circuit breakers suit external dependencies and services with failure recovery potential. Database writes, critical business operations, and services with no meaningful fallback might not benefit from circuit breakers.
How do you prevent circuit breaker cascade?
Configure circuits with different thresholds and timeouts to prevent simultaneous trips. Implement fallback strategies that don’t depend on other protected services. Monitor system-wide circuit breaker states.
What metrics indicate circuit breaker success?
Reduced cascading failures, improved system availability during partial outages, decreased resource consumption during failures, and faster recovery times indicate effective circuit breaker implementation.
How do circuit breakers handle timeout scenarios?
Timeouts count as failures for threshold calculations. Configure circuit breaker timeouts shorter than client timeouts to prevent unnecessary waiting. Some implementations differentiate between timeout and error failures.
Can machine learning improve circuit breaker configurations?
Yes, ML algorithms can analyse historical patterns to dynamically adjust thresholds and timeouts. However, simple static configurations often provide sufficient protection with less complexity.
Conclusion
The Circuit Breaker pattern provides essential protection against cascading failures in microservices architectures. Successful implementation requires careful threshold configuration, comprehensive monitoring, and integration with existing resilience mechanisms. Start with non-critical services, refine configurations based on observed behaviour, and gradually expand coverage to build truly resilient distributed systems.
For a comprehensive overview of how the Circuit Breaker pattern fits within the broader microservices ecosystem, explore our Complete Guide to Microservices Design Patterns, which covers essential patterns including API Gateway, Service Mesh, and Event Sourcing architectures.