From prompt boxes to pull requests
Twelve months ago, most teams were nudging GitHub Copilot for suggestions inside an editor. Now, agent-first tools pick up a ticket, inspect a repo, run tests, and open a pull request. GitHub’s own coding agent can be assigned issues and will work in the background, creating branches, updating a PR checklist, and tagging you for review when it’s done. The company has been rolling out improvements through mid-2025 as part of a public preview.
Third-party platforms are pushing the same end-to-end loop. Factory’s documentation describes “agent-driven development,” where the agent gathers context, plans, implements, validates, and submits a reviewable change. The pitch is not a smarter autocomplete; it’s a teammate that runs the inner loop.
This shift explains why a consumer-style subscription can’t last. In late July, Anthropic said a small slice of users were running Claude Code essentially nonstop and announced weekly rate limits across Pro and Max plans, effective August 28, 2025. Tech coverage noted cases where a $200/month plan drove “tens of thousands” of dollars in backend usage, and the company framed the change as protecting access from 24/7 agent runs and account sharing.
The message is simple: agents turn spiky, prompt-driven sessions into continuous workloads. Prices and quotas are following suit.
Why provider pricing is moving
For the last two years, flat fees and generous quotas have worked as a growth hack. But compute spend dominates model economics. Andreessen Horowitz called the boom compute-bound and described supply as constrained relative to demand. In this environment, heavy users on flat plans are a direct liability. Once agents enter the mix, metering becomes a necessity.
That also changes how vendors justify price. If a workflow replaces part of a developer’s output, pricing gravitates toward a share of value rather than a token meter. The recent quota shift around Claude Code is one of the first visible steps in that direction.
Why prices won’t float without limit
Open-source models put a ceiling on what providers can charge. DeepSeek-Coder-V2 reports GPT-4-Turbo-level results on code-specific benchmarks and expands language coverage and context length substantially over prior versions. And other models like Qwen3-235B-A22B-Instruct-2507, GLM 4.5, and Kimi K2 showing strong results across language, reasoning, and coding, with open-weight variants that teams can run privately. These are not perfect substitutes for every task, but they’re increasingly serviceable for everyday work.
Local serving stacks have also improved, but hardware remains expensive, particularly hardware with the memory and bandwidth capable of serving the largest open-weight models. The trend towards Mixture Of Expert (MOE) structured models is reducing hardware requirements, while smaller models (70B parameters and below) are rapidly improving. Together, these trends make it realistic to move a large share of routine inference off the cloud meter.
The part everyone shares: a finite pool of compute
The bigger constraint isn’t just what developers will pay, it’s what the market will pay for inference across all industries. As agent use spreads to finance, operations, legal, customer support, and back-office work, demand converges on the same GPU fleets.
Analyses continue to describe access to compute, at a workable cost, as a primary bottleneck for AI products. In that setting, the price developers see will drift towards the price the most profitable agent workloads are prepared to pay.
McKinsey’s superagency framing captures the shift inside companies: instead of a person asking for a summary, a system monitors inboxes, schedules meetings, updates the CRM, drafts follow-ups, and triggers next actions. That turns interactive usage into base-load compute.
There’s also a directional signal on agent capability. METR measured the length of tasks agents can complete with 50% reliability and found that “task horizon” has roughly doubled every seven months over several years. As tasks stretch from minutes to days, agents don’t just spike usage; they run continuously in the background, consuming compute.
A clearer way to think about the next three years
In the near term, expect more quota changes, metering, and tier differentiation for agent-grade features. The Copilot coding agent’s rollout is a good reference point: it runs asynchronously in a cloud environment, opens PRs, and iterates via review comments. That’s not a coding assistant, that’s a service with an API bill.
As the market matures, usage will bifurcate. Long-horizon or compliance-sensitive work will sit on premium cloud agents where reliability and integrations matter. Routine or privacy-sensitive tasks will shift to local stacks on prosumer hardware. Most teams will mix the two, routing by difficulty and risk. The ingredients are already there: competitive open models, faster local runtimes, and agent frameworks that run in IDEs, terminals, CI, or headless modes. (arXiv, vLLM Blog, NVIDIA Developer, Continue Documentation)
Over the longer run, per-token costs will likely keep falling, while total spend rises as agents become part of normal operations—much like cloud spending grew even as VM prices dropped. The economics track outcomes, not tokens.
What to do now
First, stabilise access. If you rely on a proprietary provider for agent workflows, and you’re big enough, you may want to consider negotiating multi-year terms. Investigate other providers like DeepSeek, GLM and Kimi and the third party inference providers that serve them (eg via OpenRouter). The Claude Code decision shows consumer-style plans can change with short notice.
Second, stand up local inference servers. A single box with a modern GPU (or 2 or 4) will run the best open models like Qwen3-Coder-30B-A3B-Instruct. Measure what percentage of your usual tasks they handle before escalation to a frontier model.
Third, wire in routing. Tools like Continue.dev make it straightforward to default to local models and switch to the big providers only when needed.
Other tools, like aider, let you split coding between architect and coder models, allowing you to drive paid frontier models for planning and architecture, and local models (via local serving options like litellm) to handle the actual code changes.
Finally, measure outcomes. Track bugs fixed, PRs merged, and lead time. That’s what should drive your escalation choices and budget approvals, not tokens burned.
Closing thought
Two things are happening at once. Providers are moving from growth pricing to profit. Open models and local runtimes are getting good enough to cap runaway bills. And over the top of both sits market-wide demand from agents in every function, all drawing from the same pool of compute.
Teams that treat agents as persistent services, secure predictable access, and run a local-based hybrid approach will keep costs inside a band as prices move. Teams that depend on unlimited plans will keep running into the same quota notices that landed last month.
Using LLMs to Accelerate Code and Data MigrationLarge language models are revolutionising code migration by embracing failure as a strategy. Airbnb’s migration of 3,500 React test files demonstrated that retry loops and failure-based learning outperform perfect upfront prompting, completing in 6 weeks what would have taken 1.5 years manually.
By scaling context windows to 100,000 tokens and using iterative refinement, organisations achieve unprecedented migration speeds. For businesses facing legacy modernisation challenges, this counter-intuitive methodology turns technical debt from a resource-intensive burden into a systematic, automated process.
The key insight: instead of trying to get migrations right the first time, LLMs excel when allowed to fail, learn, and retry—achieving 97% automation rates while maintaining code quality and test coverage.
How does Airbnb use LLMs for test migration?
Airbnb pioneered LLM-driven test migration by converting 3,500 React component test files from Enzyme to React Testing Library in just 6 weeks, using retry loops and dynamic prompting instead of perfect initial prompts.
The journey began during a mid-2023 hackathon when a team demonstrated that large language models could successfully convert hundreds of Enzyme files to RTL in just a few days. This discovery challenged the conventional wisdom that code migrations required meticulous manual effort. The team had stumbled upon something remarkable—LLMs didn’t need perfect instructions to succeed. They needed permission to fail.
Airbnb’s migration challenge stemmed from their 2020 adoption of React Testing Library for new development, while thousands of legacy tests remained in Enzyme. The frameworks’ fundamental differences meant no simple swap was possible. Manual migration estimates projected 1.5 years of engineering effort—a timeline that would drain resources and stall innovation.
Building on the hackathon success, engineers developed a scalable pipeline that broke migrations into discrete, per-file steps. Each file moved through validation stages like a production line. When a check failed, the LLM attempted fixes. This state machine approach enabled parallel processing of hundreds of files simultaneously, dramatically accelerating simple migrations while systematically addressing complex cases.
The results speak volumes about the approach’s effectiveness. Within 4 hours, 75% of files migrated automatically. After four days of prompt refinement using a “sample, tune, and sweep” strategy, the system reached 97% completion. The total cost—including LLM API usage and six weeks of engineering time—proved far more efficient than the original manual migration estimate.
What made this possible wasn’t sophisticated prompt engineering or complex orchestration. It was the willingness to let the LLM fail repeatedly, learning from each attempt. The remaining 3% of files that resisted automation still benefited from the baseline code generated, requiring only another week of manual intervention to complete the entire migration.
The key to their success wasn’t a perfect plan, but a strategy built on learning from mistakes. This strategy is known as failure-based learning.
What is failure-based learning in LLM code migration?
Failure-based learning is a counter-intuitive approach where LLMs improve migration accuracy through multiple retry attempts, adjusting prompts and strategies based on each failure rather than seeking perfect initial results.
Traditional migration approaches treat failure as something to avoid. Engineers spend considerable time crafting perfect prompts, analysing edge cases, and building comprehensive rule sets. This perfectionist mindset assumes that with enough upfront effort, migrations can proceed smoothly. Yet Airbnb’s experience revealed the opposite—the most effective route to improve outcomes was simply brute force: retry steps multiple times until they passed or reached a limit.
The methodology flips conventional wisdom on its head. Instead of viewing failed migration attempts as wasted effort, each failure becomes valuable data. When an LLM-generated code change breaks tests or fails linting, the system captures the specific error messages.
These errors then inform the next attempt, creating a feedback loop that progressively refines the migration strategy. This is the core of the approach: dynamic prompt adaptation.
Rather than maintaining static prompts, the system modifies its instructions based on accumulated failures. If multiple files fail with similar import errors, the prompt evolves to address that specific pattern. This adaptive behaviour mimics how human developers debug—learning from mistakes and adjusting their approach accordingly.
The benefits extend beyond simple error correction. Failure-based learning naturally handles edge cases that would be impossible to anticipate. Complex architectural patterns, unusual coding styles, and framework-specific quirks all surface through failures. The system doesn’t need comprehensive documentation of every possible scenario—it discovers them through iteration.
Real-world metrics validate this counter-intuitive strategy. Airbnb’s migration achieved 97% automation despite minimal upfront prompt engineering. Files that failed 50 to 100 times eventually succeeded through persistent refinement. This resilience transforms migration from a fragile process requiring perfect understanding into a robust system that adapts to whatever it encounters.
But how does this actually work in practice? The answer lies in the sophisticated retry loop architecture that powers these migrations.
How do retry loops work in automated code migration?
Retry loops create a state machine where each migration step validates, fails, triggers an LLM fix attempt, and repeats until success or retry limit—enabling parallel processing of hundreds of files simultaneously.
The architecture resembles a production pipeline more than traditional batch processing. Each file moves through discrete validation stages: refactoring from the old framework, fixing test failures, resolving linting errors, and passing type checks. Only after passing all validations does a file advance to the next state. This granular approach provides precise failure points for targeted fixes.
State machine design brings structure to chaos. Files exist in defined states—pending, in-progress for each step, or completed. When validation fails at any stage, the system triggers an LLM fix attempt specific to that failure type. A Jest test failure prompts different remediation than a TypeScript compilation error. This specialisation improves fix quality while maintaining clear progress tracking.
Configurable retry limits prevent infinite loops while maximising success rates. Aviator’s implementation uses fallback strategies when primary models fail, automatically switching to alternative LLMs like Claude if GPT-4 struggles with specific patterns. Some files might succeed on the first attempt, while others require dozens of iterations. The system adapts retry strategies based on failure patterns, allocating more attempts to files showing progress.
Parallel processing multiplies the approach’s power. Instead of sequential file processing, hundreds of migrations run simultaneously. Simple files complete quickly, freeing resources for complex cases. This parallelism transforms what would be weeks of sequential work into hours of concurrent execution. The infrastructure scales horizontally—adding more compute resources directly accelerates migration speed.
Performance optimisation techniques further enhance efficiency. The system maintains a cache of successful fix patterns, applying proven solutions before attempting novel approaches. Common failure types develop standardised remediation strategies. Memory of previous attempts prevents repetition of failed approaches, ensuring each retry explores new solution paths.
Yet all this sophisticated processing raises a question: how can an AI system truly understand the complex architecture of legacy code?
How can LLMs understand legacy code architecture?
LLMs achieve architectural understanding by processing expanded context windows up to 100,000 tokens and even larger, analysing cross-file dependencies, maintaining memory of changes, and applying consistent transformation patterns across entire codebases.
Context window scaling fundamentally changes what LLMs can comprehend. Traditional approaches struggled with file-by-file migrations that broke architectural patterns. Modern systems use greedy chunking algorithms to pack maximum code while preserving logical structures. A 100,000 token window can hold entire subsystems, allowing the model to understand how components interact rather than viewing them in isolation.
Multi-file dependency analysis emerges naturally from expanded context. LLM agents read across modules, understand how components interact, and maintain the big picture while making changes. When migrating a service layer, the system simultaneously considers controllers that call it, repositories it depends on, and tests that validate its behaviour. This holistic view prevents breaking changes that file-level analysis would miss.
Memory and reasoning capabilities distinguish modern LLM migration from simple find-replace operations. The system remembers renamed functions, updated import paths, and architectural decisions made earlier in the migration. If a pattern gets refactored in one module, that same transformation applies consistently throughout the codebase. This consistency maintenance would exhaust human developers tracking hundreds of parallel changes.
Architectural pattern recognition develops through exposure to the codebase. LLMs identify framework-specific conventions, naming patterns, and structural relationships. They recognise that certain file types always appear together, that specific patterns indicate test files versus production code, and how error handling cascades through the system. This learned understanding improves migration quality beyond mechanical transformation.
Vector database integration enhances architectural comprehension further. Systems store code embeddings that capture semantic relationships between components. When migrating a component, the system retrieves similar code sections to ensure consistent handling. This semantic search surpasses keyword matching, finding conceptually related code even with different naming conventions.
With this level of understanding, the business case for LLM migration becomes compelling. But what exactly is the return on investment?
What is the ROI of LLM-assisted migration vs manual migration?
LLM-assisted migration reduces time by 50-96% and costs significantly less than manual efforts, with Google reporting 80% AI-authored code and Airbnb completing 1.5 years of work in 6 weeks including all LLM API costs.
Time savings analysis reveals staggering efficiency gains across organisations. Airbnb’s 6-week timeline replaced 1.5 years of projected manual effort—a 96% reduction. Google’s AI-assisted migrations achieve similar acceleration, with formerly multi-day upgrades now completing in hours. Amazon Q Code Transformation upgraded 1000 Java applications in two days, averaging 10 minutes per upgrade versus the previous 2+ days requirement.
Cost breakdown challenges assumptions about AI expense. API usage for thousands of file migrations costs far less than a single developer-month. Airbnb’s entire migration, including compute and engineering time, cost a fraction of manual estimates. The pay-per-use model makes enterprise-scale capabilities accessible to SMBs without infrastructure investment.
Quality metrics dispel concerns about automated code. Migration systems maintain or improve test coverage while preserving code intent. Google’s toolkit achieves >75% of AI-generated changes landing successfully in production. Automated migrations often improve code consistency, applying modern patterns uniformly where manual efforts would vary by developer.
Communication overhead reduction multiplies savings. Manual migrations require extensive coordination—architecture reviews, progress meetings, handoffs between developers. LLM systems eliminate most coordination complexity. A small team can oversee migrations that would traditionally require dozens of developers, freeing skilled engineers for innovation rather than maintenance.
Risk mitigation strengthens the business case further. Manual migrations introduce human error, inconsistent patterns, and timeline uncertainty. Automated systems apply changes uniformly, validate comprehensively, and provide predictable timelines. Failed migrations can be rolled back cleanly, while partial manual migrations often leave codebases in unstable states.
Decision frameworks for SMB CTOs become clearer when considering total cost of ownership. Legacy system maintenance grows more expensive over time—security vulnerabilities, framework incompatibilities, and developer scarcity compound costs. LLM migration transforms a multi-year budget burden into a tactical project measured in weeks, fundamentally changing the economics of technical debt reduction.
These compelling benefits naturally lead to the question: how can you implement this in your own organisation?
How to implement retry loops in LLM migration?
Implementing retry loops requires breaking migrations into discrete steps, setting validation checkpoints, configuring retry limits, using fallback models, and establishing confidence thresholds for manual intervention triggers.
Step-by-step implementation begins with decomposing the migration into atomic operations. Each step must have clear success criteria—tests pass, linting succeeds, types check correctly. Airbnb’s approach created discrete stages: Enzyme refactor, Jest fixes, lint corrections, and TypeScript validation. This granularity enables targeted fixes when failures occur.
Validation checkpoint configuration determines migration quality. Each checkpoint runs specific tests relevant to that migration stage. Unit tests verify functionality preservation. Integration tests ensure component interactions remain intact. Linting checks maintain code style consistency. Type checking prevents subtle bugs. These automated gates catch issues immediately, triggering appropriate remediation.
Retry limit strategies balance thoroughness with efficiency. Simple transformations might warrant 3-5 attempts, while complex architectural changes could justify 20+ retries. Dynamic limits based on progress indicators work best—if each retry shows improvement, continue iterating. Stalled progress triggers fallback strategies.
Fallback model implementation provides resilience when primary approaches fail. Systems automatically switch between models based on failure patterns. GPT-4 might excel at logic transformation while Claude handles nuanced refactoring better. Some implementations use specialised models fine-tuned on specific framework migrations.
Error handling mechanisms must capture detailed failure information. Stack traces, test output, and validation errors feed back into retry prompts. Systems track which error types respond to which remediation strategies, building a knowledge base of effective fixes. This accumulated wisdom improves future migration success rates.
CI/CD pipeline integration ensures migrations fit existing development workflows. Automated pipelines using GitHub Actions, ESLint, and formatters validate every generated file. Migrations run in feature branches, enabling thorough testing before merging. Rollback procedures provide safety nets if issues surface post-deployment.
Which companies offer LLM migration services?
Major providers include AWS with Amazon Q Code Transformation, Google’s internal migration tools using Gemini, and specialised platforms like Aviator that offer LLM agent frameworks for Java to TypeScript conversions.
AWS Amazon Q Code Transformation represents the most comprehensive commercial offering. The service automates language version upgrades, framework migrations, and dependency updates. It analyses entire codebases, performs iterative fixes, and provides detailed change summaries. Integration with existing AWS development tools streamlines adoption for teams already using the ecosystem.
Google’s Gemini-based approach showcases internal tool sophistication. Their toolkit splits migrations into targeting, generation, and validation phases. Fine-tuned on Google’s massive codebase, it handles complex structural changes across multiple components. While not publicly available, it demonstrates the potential of organisation-specific tools.
Aviator’s LLM agent platform specialises in complex language transitions. Their multi-agent architecture uses specialised models for reading, planning, and migrating code. The platform excels at maintaining architectural consistency during fundamental technology shifts like Java to TypeScript migrations. Built-in CI/CD integration and comprehensive error handling make it suitable for production deployments.
Open-source alternatives provide flexibility for custom requirements. LangChain and similar frameworks enable building bespoke migration pipelines. These tools require more implementation effort but offer complete control over the migration process. Organisations with unique codebases or specific compliance requirements often prefer this approach.
Selection criteria for SMBs should prioritise accessibility and support. Managed services like Amazon Q reduce implementation complexity, providing immediate value without deep expertise requirements. Platforms focusing on specific migration types often deliver better results than generic tools. Cost models matter—pay-per-use APIs enable starting small and scaling based on success.
Feature comparison reveals distinct strengths across providers. AWS excels at Java version migrations and AWS service integrations. Google’s tools handle massive scale with sophisticated validation. Aviator specialises in cross-language migrations with strong typing preservation. Understanding these specialisations helps match tools to specific migration needs.
One technical challenge remains: how do these systems handle the massive codebases they need to process?
FAQ Section
Why do LLM migrations fail?
LLM migrations typically fail due to insufficient context, complex architectural dependencies, outdated third-party libraries, or attempting perfect initial prompts instead of embracing iterative refinement approaches.
The most common failure stems from treating LLMs like deterministic tools. Developers accustomed to precise programming languages expect consistent outputs from identical inputs. LLMs operate probabilistically, generating different solutions to the same problem. This variability becomes a strength when combined with retry mechanisms but causes frustration when expecting perfection.
Complex architectural dependencies pose particular challenges. Legacy systems often contain undocumented relationships between components. A seemingly simple function might trigger cascading changes throughout the codebase. Without sufficient context about these hidden dependencies, LLMs generate changes that break distant functionality. Expanding context windows and thorough testing helps, but some architectural complexity requires human insight to navigate successfully.
Is LLM migration cost-effective for small businesses?
Yes, LLM migration is highly cost-effective for SMBs, often costing less than one developer-month of work while completing migrations that would take years manually, with pay-per-use API pricing making it accessible.
The economics favour smaller organisations particularly well. Large enterprises might have teams dedicated to migrations, but SMBs rarely possess such luxury. A typical developer costs $10,000-15,000 monthly, while API costs for migrating a medium-sized application rarely exceed $1,000. The time savings multiply this advantage—developers focus on revenue-generating features rather than maintenance.
Pay-per-use pricing removes barriers to entry. No infrastructure investment, no model training, no specialised hardware. SMBs can experiment with small migrations, prove the concept, then scale based on results. This iterative approach manages risk while building organisational confidence in AI-assisted development.
How to validate LLM-generated code changes?
Validation involves automated testing suites, CI/CD integration, regression testing, shadow deployments, code review processes, and maintaining feature branch isolation until all checks pass successfully.
Comprehensive test coverage forms the foundation of validation. Existing tests verify functionality preservation, while new tests confirm migration-specific requirements. The key insight: if tests pass before and after migration, core functionality remains intact. This assumes good test coverage—migrations often reveal testing gaps that manual review would miss.
Shadow deployments provide production-level validation without risk. The migrated system runs alongside the original, processing copies of real traffic. Performance metrics, error rates, and output comparisons reveal subtle issues that tests might miss. This parallel operation builds confidence before cutting over completely.
Can LLMs migrate proprietary or custom frameworks?
LLMs can migrate proprietary frameworks by providing sufficient examples and context, though success rates improve with retry loops, custom prompting strategies, and human-in-the-loop validation for edge cases.
The challenge with proprietary frameworks lies in pattern recognition. Public frameworks appear in training data, giving LLMs inherent understanding. Custom frameworks require explicit education through examples and documentation. Success depends on how well the migration system can learn these unique patterns.
Prompt engineering becomes crucial for proprietary migrations. Including framework documentation, example transformations, and architectural principles in prompts helps LLMs understand custom patterns. The retry loop approach excels here—each failure teaches the system about framework-specific requirements.
What programming languages can LLMs migrate between?
LLMs successfully migrate between most major languages including Java to TypeScript, Python 2 to 3, COBOL to Java, and legacy assembly to modern languages, with effectiveness varying by language pair complexity.
Language similarity significantly impacts success rates. Migrating between related languages (Java to C#, JavaScript to TypeScript) achieves higher automation rates than distant pairs (COBOL to Python). Syntax similarities, shared paradigms, and comparable standard libraries ease transformation.
Modern to modern language migrations work best. These languages share contemporary programming concepts—object orientation, functional elements, similar standard libraries. Legacy language migrations require more human oversight, particularly for paradigm shifts like procedural to object-oriented programming.
How long does LLM migration take compared to manual migration?
LLM migrations typically complete 10-25x faster than manual efforts, with Airbnb’s 6-week timeline replacing 1.5 years and Google achieving 50% time reduction even with human review included.
The acceleration comes from parallel processing and elimination of human bottlenecks. While developers work sequentially, LLM systems process hundreds of files simultaneously. A migration that would occupy a team for months completes in days. Setup time adds overhead, but the exponential speedup quickly compensates.
Human review time must be factored into comparisons. LLM migrations require validation, but this review process moves faster than writing code from scratch. Developers verify correctness rather than implementing changes, a fundamentally faster cognitive task.
What skills does my team need for AI migration?
Teams need basic prompt engineering understanding, code review capabilities, CI/CD knowledge, and ability to configure validation rules—significantly less expertise than manual migration would require.
The skill shift favours most development teams. Instead of deep framework expertise for manual migration, teams need evaluation skills. Can they recognise correct transformations? Can they write validation tests? These verification skills are easier to develop than migration expertise.
Prompt engineering represents the main new skill, but it’s approachable. Unlike machine learning engineering, prompt crafting uses natural language. Developers describe desired transformations in plain English, refining based on results. Online resources and community examples accelerate this learning curve.
How to measure success in LLM-driven migrations?
Success metrics include code coverage maintenance, test pass rates, build success rates, performance benchmarks, reduced technical debt metrics, time-to-completion, and total cost of ownership.
Quantitative metrics provide objective success measures. Test coverage should remain stable or improve post-migration. Build success rates indicate compilation correctness. Performance benchmarks ensure migrations don’t introduce inefficiencies. These automated metrics enable continuous monitoring throughout the migration process.
Qualitative assessments complement numbers. Developer satisfaction with the migrated code matters. Is it maintainable? Does it follow modern patterns? Would they have written it similarly? These subjective measures often predict long-term migration success better than pure metrics.
Can AI really migrate my entire codebase automatically?
AI can automate 80-97% of migration tasks, but human review remains essential for business logic validation, security considerations, and edge cases that require domain expertise.
The realistic expectation sets AI as a powerful assistant, not a complete replacement. The vast majority automates successfully, while complex edge cases need human judgment. This ratio holds across many migrations.
Business logic validation particularly requires human oversight. While AI can transform syntax and update frameworks, understanding whether the migrated code maintains business intent requires domain knowledge. Security implications of changes also warrant human review, especially in sensitive systems.
What’s the catch with using LLMs for technical debt?
The main considerations are API costs for large codebases, need for robust testing infrastructure, potential for subtle bugs requiring human review, and initial setup time for retry loop systems.
API costs scale with codebase size and complexity. While individual file migrations cost pennies, million-line codebases accumulate charges. However, these costs pale compared to developer salaries for manual migration. Organisations should budget accordingly but recognise the favourable cost-benefit ratio.
Testing infrastructure requirements can’t be overlooked. LLM migrations assume comprehensive test coverage to validate changes. Organisations with poor testing practices must invest in test creation before attempting migrations. This investment pays dividends beyond migration, improving overall code quality.
Conclusion
The counter-intuitive approach of embracing failure in LLM-driven code migration represents a paradigm shift in how we tackle technical debt. By allowing AI systems to fail, learn, and retry, organisations achieve automation rates previously thought impossible. The success stories from Airbnb, Google, and others demonstrate that this methodology isn’t just theoretical—it’s delivering real business value today.
For SMB CTOs facing mounting technical debt, the message is clear: LLM-assisted migration has moved from experimental to essential. The combination of accessible pricing, proven methodologies, and dramatic time savings makes it feasible for organisations of any size to modernise their codebases. The question isn’t whether to use LLMs for migration, but how quickly you can start.
The future belongs to organisations that view technical debt not as an insurmountable burden but as a solvable challenge. With LLMs as partners in this process, what once required years now takes weeks. The tools exist, the methodologies are proven, and the ROI is undeniable.
Your technical debt is actively costing you money and slowing down innovation. The tools to fix it are now faster and more affordable than ever. Start a small pilot project this quarter and see for yourself how failure-based learning can clear years of debt in a matter of weeks.
SoftwareSeni AI Adoption UpdateWe’ve finalised our AI usage policy and are moving from ad-hoc adoption to systematic implementation. For those of you already providing AI tools to our embedded developers – thank you for leading the way. We’re now scaling this across all teams.
Timeline for Implementation
June: All developers received access to Copilot, Windsurf, or Cursor. We ran competitive coding challenges to rapidly upskill and identify best practices. We’ve integrated training on maintaining IP protection and data confidentiality when using AI coding assistants on a codebase into our practices.
Our prompt engineering templates and knowledge sharing systems are live. We expect this to standardise the efficiency gains we’ve been seeing in pilot usage.
July: Full deployment across non-dev teams, pilot projects to benchmark velocity improvements, and an integration-focused hackathon. We hope to have concrete metrics to share on productivity gains.
The Future Is Moving Fast
The technical landscape is shifting fast. We know some of you are ahead of us here, but we’re committed to keeping on top of emerging best practices and tools so our developers can continue to deliver value to your team.
If you have any questions or just want to talk about the future of developing software products don’t hesitate to get in touch.
Agentic Coding For Teams – Tools and TechniquesAI coding assistants have advanced from providing smart autocomplete to building complete albeit simple products. This advance has been fuelled by a combination of improvements in model quality and coding-focused training along with new tooling that supports rapid code development.
We’re going to cover the different levels of usage with AI coding assistants and go into detail on the key strategies that developers are using to multiply their productivity with these tools.
We’ll also discuss how context and compute impact results, share practical strategies for teams and point you to sources for more in-depth information.
The Tools – plenty to choose from
There are currently two main categories of coding tools – first generation, IDE based tools like Github Copilot and Cursor that are in a constant race to maintain feature parity with each other while also doing their best to integrate ideas from the second generation of coding tools – the agent-based paradigm spear-headed by Claude Code.
This paradigm is starting to be referred to as Agentic Development Environments (ADE).
There are also browser-based tools like v0, replit, lovable and bolt.new, but we will be sticking to tools that are likely to be used by teams working on substantial, local codebases.
Below is a non-exhaustive table of AI coding tools that we examined while writing this article.
| IDE Based | ADE Based | Open Source |
| GitHub Copilot | Amp | Cline |
Levels of AI Coding Assistant Use
Different tasks and different developers require different approaches to using AI. Sometimes fine-grained control is needed. At other times, for well defined problems and “boilerplate”, an AI coding assistant can shoulder more of the effort.
We’ve broken down the use of coding assistant to 4 levels:
- Autocomplete
- Pair programming
- Feature Lead
- Tech Lead
Autocomplete – Line level AI-assistance
This style of coding assistant usage is good for working in existing codebases and making multiple edits or refactoring. It is a feature of the leading IDE-based tools.
A good AI autocomplete can fill in boilerplate like type information and assist with repetitive code such as mapping values between objects or marshalling and un-marshalling data formats.
It can also predict where your next change needs to be made, allowing you to jump to edit spots. For example, adding a typed argument to a function definition will lead to the required import statement at the top of the file.
For more detailed additions, where some mind-reading would be required, writing a short comment about the next step in the function you’re writing can prime the autocomplete enough for it to provide a first pass you can craft into the form you need.
Implementations
- Cursor’s tab completion was its initial claim to fame. It used a fast, dedicated model to generate completions.
- Cursor was followed by Copilot and Windsurf
- Now AmpCode, an agent-based AI coding assistant, has added a tab completion mode
- File oriented tools like Cline and Roo don’t provide tab completions despite working within an IDE
Pair Programming
The next level up uses IDE-based AI coding assistants like Cursor, Windsurf, Cline, and Roo. It operates at the function level, instructing the AI in writing blocks of code, and makes use of the chat panel of the IDE to instruct the coding assistant and manual edits in the file windows to tweak generated code.
We call this “Pair Programming” because code is written in dialogue with the coding assistant, with the developer moving between prompting in the chat interface and revising code that the AI writes.
Getting the best performance out of the coding assistant requires giving it all the background knowledge about the project, or the particular task you’re working on, that it will need. It will know that if the file is typescript that it has to code in typescript, but it won’t know which libraries you want it to use, or what other APIs/sub-systems it has access to.
The developing standard for providing this information is to use “Rules” files. Coding assistants each have their own file or directory of files where they look for instructions to load into their context at the beginning of a session or a new conversation.
Rules can provide guidance on coding conventions, project structure, library preferences, commands to perform or any other information or action you need.
You can even use the coding assistant to update or write new rules as the opportunity (or problem) arises.
Each coding assistant has its own convention for rules file names and locations. Check the documentation.
Feature Lead
For this level we are defining feature development as anything that involves adding code across multiple files and/or integrating functionality into an existing codebase
This is where coding assistants start to offer a substantial productivity boost. It’s also where programming takes a step up the ladder of abstraction from code to specifications for the code.
Here is a quote from Robert C. Martin in his book “Clean Code” from 17 years ago:
“Indeed some have suggested that we are close to the end of code. That soon all code will be generated instead of written. That programmers simply won’t be needed because business people will generate programs from specifications.
Nonsense! We will never be rid of code, because code represents the details of the requirements. At some level those details cannot be ignored or abstracted; they have to be specified. And specifying requirements in such detail that a machine can execute them is programming. Such a specification is code.”
At this level, typing is no longer the limiting factor on how quickly code can be produced. Instead, clarity of instruction, the specifications given to the coding assistant, and generating those specifications, is what sets the limit.
This has lead to the adoption of a technique sometimes known as “Product Requirements Document Driven Development” (PRDDD). With detailed specifications determining the success in using AI coding assistants, it turns out you can use AI coding assistants to help you write the detailed specifications you need.
The document creation process for PRDDD follows this path:
PRD → Technical Specification → Implementation Plan → Checklists → Task lists
The PRD is created in a discussion with an AI like Gemini Pro, Claude Opus or O3 instructed to ask questions and resolve unknowns and ambiguities by asking you for clarification.
The PRD is used in a similar process to create a Technical Specification from it. Each new document is used to create the next.
It is a common strategy to use a second provider’s model to critique and refine the PRD, technical specification and implementation plan. And of course a senior developer should also review and refine them.
Next, you create as many Checklists as needed. You choose how you break down your project: services, implementation phases, etc. Aim for clarity of purpose. You want a checklist to be dedicated to one clear end.
Checklists are then turned into detailed Task Lists by the coding assistant.
The coding assistant can be prompted to turn an item on a checklist into a detailed task list for a mid-level developer (targeting a junior developer level will create too many steps or be over-simplified).
A detailed walk through of the process is available on specflow.com.
Code then verify
Then it is simply a matter of instructing the coding assistant to complete the items in a task list, marking them off as it goes.
Then, with a cleared context or in a new session, instruct the coding assistant to verify the completion of the tasks.
There are workflow tools that automate opinionated versions of PRDDD:
Claude Simone (Claude Code only)
Claude Taskmaster (All IDE-based tools)
Tech Lead
This level involves working at the application level and leverages Agent Orchestration instead of assistant management.
Agent Orchestration still uses PRDDD but in parallel across multiple agents.
Depending on your coding assistant you will use either in-tool orchestration or manual Orchestration.
Tools with inbuilt orchestration to launch multiple agents (called sub-agents or tasks):
- AmpCode
- Jules
- Cursor (new background agents in beta)
- Claude Code (using the Task tool)
Manual orchestration is built around terminal-based coding assistants like Claude Code and OpenAI Codex. It combines Git Worktrees + tmux to work on multiple features simultaneously. This process works with any terminal based coding assistant.
Its popularity has led to specialised tools for managing manual orchestration:
The Two Practices That Maximise AI Coding
No matter which level of AI coding usage you are working at, there are two key practices you need to get right to get the best results from AI coding assistants are:
- Managing Context
- Burning Compute
Managing Context
AIs are getting longer context windows, but their performance suffers as their context window fills. Managing the context window is currently a key focus of developers using agentic coding tools and the growing awareness of the impact of context window contents on agent performance is causing “prompt engineering” to give way to “context engineering”.
Concise, targeted documentation is needed to leave space for the AI to read code, write its own code into the context, reason about it, make tool calls and perform management tasks. Going overboard on “rules” files can negatively impact the quality of the code an assistant can produce, and how “agentic” it can be.
Until the tools are smart enough to optimise context for you, follow these tips to maximise information while minimising tokens:
- Use diagrams in mermaid format including
- Architecture diagrams
- Sequence diagrams
- State machine diagrams
- Entity-relationship diagrams
- You can get the LLM to “draw” them for you
- Include a file tree for the project
- Use API references for libraries, services and modules(in house and third party) rather than the actual code.
- You can reference specific documents in your prompt (most coding assistants use an @filename command) and provide instructions to read any global documentation in the coding assistant’s rules file.
Use sub-agents/tasks.
Sub-agents act like a fresh context window to complete a task.
- The main agent context will grow by only the sub-agent’s response, maintaining coherency
- The sub-agent will load the same rules files and other default documentation along with any other files or text supplied by the agent.
- You want briefing the sub-agent to be file-based or involve minimal text exchange (like a task list)
- Have the sub-agent make direct changes to files and report back a summary or a success/failure message
- Note: You may need to provide rules on when and how to use sub-agents in your coding assistant’s rules file.
Burning Compute
The more inference time compute an AI uses the better chance the result is correct. Prompt tokens and generated tokens contribute to the compute.
Chain of Thought (CoT), instructing a model to document a thinking process as part of its response, is an example of burning more compute to improve results.
Reasoning models are LLMs that have been trained to generate an intrinsic form of CoT. In Claude Code you can set the thinking budget for Claude Opus or Claude Sonnet to expend on a response using “think”, “think hard”, “think harder”, and “ultrathink” in your prompt text to control how much extra compute you want to use.
Best-of-n is another technique, where the same prompt is run “n” times and best result used. OpenAI’s O1-pro model costs more than O1 because it uses the Best-of-n approach to generate answers, making it “n” times the cost of the default O1 model. They are using the same technique for producing high quality answers from O3-pro. This increased usage of compute also means a longer time to return an answer.
Using Best-of-n smaller models can reach the performance of larger models if given enough compute via multiple runs, but there are limits to this size/compute trade-off.
All this means trying multiple times at a failed task is a reasonable strategy. But make sure you do follow up attempts with a fresh, strategically primed context including what has been tried and didn’t work. You can get the coding assistant to provide that try/fail summary before starting a new conversation.
After 3 failures you should try a model from another provider to solve the issue or to get insight on the failure.
Burning Compute & PRDDD
PRDDD uses iterative decomposition of your goals to cache compute.
Using AI to break down a task into small steps, each supported by a detailed prompt of system and process documentation, leverages the earlier compute that created the documentation.
Inference over a detailed prompt for even a simple task gives you the best chance of success by maximising compute. But you need to be sure that there is enough headroom in the agent’s context for the detailed prompt along with the agent’s thinking, tool responses and file changes in order to get the best results.
Everyone wants to use less compute to save money, but using more compute can get you single-shot success instead of burning more compute (and time) iterating over poorly (cheaply) specified tasks.
Starting a fresh session and instructing the coding assistant to verify tasks it has completed spends more compute while using a shorter context providing better coherence and better outcomes.
First you do it, then you do it right
This is a technique that builds on the idea of burning compute as well as the old engineering adage: “First you do it, then you do it right, then you do it fast”.
Start your code change in a new branch. First use the agent to make a plan for the executing the change. Have the agent maintain an append-only log where it records files used, decisions made, the questions it comes up with, the answer to those questions and any surprises while it executes the plan. Once the coding task is completed commit it and close the branch. Then have the agent review the diff and update the plan with any insights. Finally, roll back to before the branch and then re-run the code change with the updated plan and the log to guide the agent in a second run through.
Practices for Teams
- Partition your codebase
- Modularity with strong decoupling and clear interfaces between services is key to multiple team members using AI coding assistants
- Modularity also decreases the size of the context needed to hold relevant information
- Limit the coding assistant’s reach to targeted folders
- Have clearly documented standards that are used across all coding assistant sessions
- Have a place to share prompts, rules files, and processes across the team
- Make use of tools like SpecStory for capturing coding sessions to extract prompts and coding strategies
- Have clear boundaries on what coding assistants can and cannot touch. These are places where any breakages could have negative business impacts.
- APIs
- Data migrations
- Configuration scripts
- Tests
Worth Reading
The sources below cover the current status quo in best practices for using AI coding assistants as of June 2025. They are worth reading. The AI High Signal list on Twitter is a good place to watch for the emergence of new techniques and tools and the AI News newsletter delivers daily summaries of trending topics.
- Revenge of the junior developer
- My AI Skeptic Friends Are All Nuts
- Beyond Code-Centric: Agents Code but the Problem of Clear Specification Remains
- Specflow
- Vibe Coding 101 for Software Engineers
- Field Notes From Shipping Real Code With Claude
- You are using Cursor AI incorrectly
- The Agentic Systems Series
- How to fix your context
- The Prompt Engineering Playbook for Programmers
- My AI Prompt Engineering Playbook for Developers
- A 3-step AI coding workflow for solo founders
- LLM Codegen go Brrr – Parallelization with Git Worktrees and Tmux
- Field notes: git worktree pattern
- Claude Code: Best practices for agentic coding
- AI High Signal list on Twitter
- AI News newsletter
“Agentic” coding tools are the new hot AI-wrapper product. They seem to promise that they will make your developers super-humanly productive by turning them into managers delegating and approving the work of as many AI coding assistants as you can afford.
They are also spoken of as the next step in the evolution of programming. As we went from filling memory by flipping switches to manually punching cards to encode machine instructions then on to assembly language and from there to structured programming languages that required a compiler to generate machine code, now we will all be programming in English (or your preferred human language) via conversation with AI.
This new conversational style of “programming” is also causing people to predict the end of the IDE as the new agentic coding tools do away with or simplify text editors as part of their feature set.
Cursor was the editor with built-in AI. Now you have tools like Factory and Jules that reduce the editor to a minimal box where you can make basic changes if you really must. If you have a problem with your agentic AI assistant’s code, or if you just want to explore what they’ve written, you’ll need to tab away to your old IDE.
AI-assisted coding is the second killer app after ChatGPT (which took just 2 months to reach 100 million users) and model providers are leaning in hard to capture this market, shifting the training of their models to emphasise coding ability and coding processes.
And on the product side, the industry saw the valuations of Cursor and the purchase price of WindSurf and started pumping out their own variations and visions for the future of AI-assisted coding.
Below we run you through the main contenders for agentic coding assistants. “Agentic” is slowly gravitating towards meaning multi-agent systems performing multiple (if not hundreds) of actions on their own to complete a task. Coding assistants are all heading that way. Having many agents doing focused tasks and expending higher levels of compute is a clear strategy for getting better results out of AI.
But these coding tools are mainly single agent assistants and “agentic” here means that the coding assistant will decide what to do itself across many, even hundreds, of actions.
Some developers simply run multiple instances of these single agent assistants simultaneously. Here is the CPO of Anthropic, makers of Claude, explaining that this is exactly what happens in Anthropic, where developers have become “orchestrators” of Claude, and yes, that is going to impact hiring practices.
The Agentic Coding Tools
Claude Code
The first widely used agentic coding assistant, Claude Code was released in 2025. Anyone who has been closely following the tech for more than a year will recognise the influence of the open source AI coding tool aider. Claude Code took the terminal-based, conversational model and added MCP-based tool calling, giving the assistant more actions to perform, including interacting with files, searching the web for solutions, pushing changes to your git repository and anything else you wanted to wire it up to.
If you wanted to look at the code you had to switch to your IDE. For VS Code and the like you could choose to run Claude in a terminal window and watch it work while giving it directions.
Running multiple instances of Claude Code in a terminal using a session manager like tmux became a power move for developers who could afford the expense of all the tokens. This practice was codified in tools like Claude Squad.
Devin
Devin made a splash when it was announced in March 2024. Its big selling point was that it was built by a team of competitive coders, who obviously must know a thing or two about software development. Unlike Claude Code, which anyone who could be bothered to sign up for an Anthropic API key could access on a PAYG basis, it was infamous for being expensive and hard to get access to. It became generally available in December 2024.
With the release of Claude Code in the following February, which gave developers a new sense of just how expensive coding can be when every action can consume 100K+ tokens, Devin no longer seemed over-priced.
Devin has an in-house fine-tuned model for code generation. It also uses dedicated agents for different purposes (editing files, interacting with the command line, etc) that can interact with each other to get things done.
In May 2025 OpenAI announced Codex, their own dedicated AI coding assistant running on their models. Codex is cloud-based and can work with your repositories. It is only available in ChatGPT Pro and ChatGPT for Teams.
At the same time OpenAI also announced Codex CLI, an open source Claude Code clone that the community quickly updated to make it work with other model providers and inference services.
Jules
Google announced Jules, their cloud-based coding assistant at Google I/O in May 2025. It is powered by their SOTA Gemini models.
Jules can connect to your repositories and it uses a notion of “tasks” to allow you to direct it to work on several things at once. It is still in early beta and provides 60 actions per day for you to try it out.
AmpCode
AmpCode looked at how developers were using Claude Code, especially developers running multiple instances of Claude Code to do more at once, and built an interface around that idea. They extended it, calling multiple instances “Threads” and making it team based, so everyone involved can see what is being worked on. They recently let the agents in a Thread spawn sub-agents that can run in parallel.
AmpCode is available as a VS Code plugin and as a node-based CLI tool.
Factory
Factory is the latest AI coding tool to come out of stealth mode. It is a browser-based tool, like Jules, but unlike it Jules it also has a “bridge” app that runs on your machine, allowing it to access local files and the command line.
Factory uses the idea of “Droids”, which are each a specialised collection of prompts and tools. There are Knowledge, Product, Code and Reliability Droids.
The idea with Factory is that you have multiple sessions running, each in its own browser tab or window, each using a particular type of Droid to perform tasks.
With the right tool permissions, Droids can update your local or Github repositories directly. And the interface lets you work as a designer and code reviewer instead of a programmer. You will want to pop out to your IDE opened in your repository if you want to explore any changes or make your own fixes.
Different Interfaces But Same Models
Each of the tools we’ve covered has their own take on how AI-based coding is going to be performed. Some are more different than others, but we are in the early, exploratory stage of this paradigm.
In trialing these tools for this article (except for Devin) one thing was obvious: no tool is magical. They all feel the same and that is because they are all built on top of the same 3 model providers.
The SOTA models are all pretty close together in the evals. No bespoke interface, despite any lengthy, heavily tweaked prompts, is going to extract better code out of the models than any other product.
Pick Your Coding Assistant
The only way to get better code out of a model is more compute – more tokens, more context, more runs at the same task. It is pay-to-win, but with open source tools like Cline and less expensive, high ability coding models like DeepSeek, you do have cheaper options.
An effective coding assistant does more than just generate code, it also performs actions. There are differences in models’ abilities to choose, execute and respond to actions, with Claude being the leader in this regard, but it is a feature all model providers are training for so you can expect the gaps to close in the near future.
With models matching on quality, and tools racing for feature parity, and everyone competing for your $$$, it’s a good time to be trialling tools and seeing what works best for your team.
Your AI coding strategies can be transplanted from one tool to another. Their output is raw code in your repositories, so there is no lock-in.
Coding is going to be AI-assisted. There is no avoiding it. Start working with the tools now so your team can evolve alongside the technology and not be left behind.
How to Use Permissions To Minimise the Damage When Your Security is BreachedYou have security measures in place, right? We made a guide to the basic security practices everyone should have in place. So let’s say you’ve got the basics down. Nothing is perfect and cybercriminals have that automated relentlessness. So what happens when one of your security measures fails?
Yes, we say when, not if.
What if someone clicks a phishing link and gets hit with malware or even an old-fashioned disgruntled employee decides to cause problems for you?
The damage depends on what they can access. That’s where permission management comes in. This article walks you through how to limit the blast radius of a security incident using access controls, segmented data, and a few smart defaults. It works across your devices, your shared storage, your intranet and team services like Google Workspace and Microsoft 365/Teams.
Let’s get started.
1. Start With Stopping Admin Rights Everywhere
No one should be a local administrator on their machine unless they need to be. This one change makes a huge difference.
Why it matters
If malware gets in through email or a bad download and the user has admin rights, it can install more malware, mess with system settings, or move sideways to other systems. Remove admin rights, and a lot of that just doesn’t work.
If someone does need administration privileges, they should be working in standard user mode except when administration privileges are required.
What to do
- Set up all company laptops and desktops with standard user accounts.
- If someone needs admin rights (e.g., IT), create a separate admin account for them to use only when necessary.
- Use MDM tools (Google endpoint management, Microsoft Intune, Jamf, etc.) to enforce this and push out settings.
Add-on: EDR + Updates
EDR is basically permissions for apps. It stops apps from doing things they shouldn’t.
- Install and manage an EDR (Endpoint Detection and Response) tool on all devices (Microsoft Defender for Business, ESET Endpoint Security, Trend Micro Apex One, Sophos Intercept X, CrowdStrike Falcon).
- Enforce automatic updates for OS and key apps.
- Encrypt drives (BitLocker for Windows, FileVault for macOS) and enable device wipe for lost/stolen gear.
2. Be Selfish With Shared Storage
The goal here is simple: if someone breaks into one account, how many files can they touch? With bad storage hygiene, the answer might be all of them.
Where it goes wrong
Shared folders are always popping up as new projects start or new processes appear. People are added or, just to make it easy, everyone in the org can access them.
Most of the time these permissions are never reviewed or tightened.
What to do
- Segment storage by team or project. No more giant “shared” folder for the whole company.
- In Google Workspace: use Shared Drives instead of individual Drives. That way, when someone leaves, the files stay.
- In Microsoft 365/Teams: use Teams-based document libraries for file access rather than shared folders in OneDrive.
- Turn off or restrict “Anyone with the link” sharing.
Run permission reviews
- Every quarter (or every big org change), check: who has access to what?
- Remove people from folders, Teams, Drives they no longer need.
- If someone leaves the company, remove them from all groups and shut down access the same day.
External sharing
You want to avoid this where you can, but in a world of contractors and consultants sometimes you need to give outsiders access. Just be sure to give them as little access as possible.
- Use approved domains in Google Workspace.
- In Microsoft 365, restrict guest access with policies.
- Set links to expire or restrict them to specific people.
3. Use a “Need To Access” mindset
Just because someone is part of your business doesn’t mean they should need access to everything. Or, to be more serious, use a “Zero Trust” model. No-one gets access to anything unless they provably need it.
Segment Information and Functionality
- Finance doesn’t need access to Engineering’s wiki.
- Engineering doesn’t need access to HR’s files.
- A contractor doesn’t need access to your Slack history.
Use groups and roles to manage access:
- In Google Workspace, assign access to Sites, Docs, and Calendars based on Groups.
- In Microsoft Teams, create private channels for sensitive conversations (e.g., leadership, HR, finance).
Use conditional access policies
- Only allow access to critical apps from managed devices.
- Block logins from unknown IPs or suspicious locations.
- Require re-authentication or step-up MFA for sensitive actions.
These policies exist in both Google and Microsoft ecosystems. Use them.
4. Use MFA & Password Managers For Everything All The Time
MFA
This is non-negotiable. This shifts account permissions, limiting them to the individual with the MFA key.
Every account should require Multi-Factor Authentication (MFA). Without it, a phished password is compromised service. With it, a phished password is still blocked at login.
Enable MFA for all Google Workspace or Microsoft 365 accounts. If you’re not already doing this, stop reading and go do it.
You will need to install an app. Google Authenticator is available on Android and IOS. Microsoft Authenticator is also available on Android and IOS. They are easy to use. Add a new MFA login is normally as simple as scanning a QR code (never scan random QR codes).
Password Managers
Shared passwords are a liability. Simple passwords that are easy to remember are also a liability, If you must share access to a service rather than providing individual accounts, use a business password manager.
There are good options in this segment. Get your team onto one of these:
Use group vaults, share credentials securely, and train your team to never email or message passwords.
5. Lockdown Internal Apps and Collaboration Tools
The last thing you want is an attacker getting access to internal apps, wikis, or, especially, chat platforms. Staff should only have permissions to access the chats on a need-to-have basis.
What to lock down
- Google Chat rooms: make sensitive ones private, control invites.
- Slack: use private channels, restrict integrations, disable public link sharing.
- Teams: use private channels, restrict who can create them, review membership regularly.
Review OAuth app access
Both Google and Microsoft platforms let third-party apps request broad access to user data. Audit those permissions and revoke what’s not needed.
Here’s how to review OAuth app access on Google Workspace. And here’s how to review OAuth app access on Teams.
Putting It All Together
Here’s the order of operations for getting all the permissions in place:
- Remove local admin rights.
- Enforce MFA.
- Centralise access to shared files, use team-based permissions.
- Review permissions regularly.
- Use private channels/rooms in chat and collaboration tools.
The less access people have by default, the less there is to clean up when something goes wrong. And if you set it all up right, cleaning up becomes: turn off access, restore files, and get on with your day.
That’s the real benefit of this approach. Not just damage prevention, but fast recovery.
That’s all there is. Go limit that blast radius.
Start with devices. Move on to storage. Then wrap up with internal systems. And finally, stop shared passwords and enforce MFA across the board.
Each step is simple. The result is a business that’s hard to hurt, and quick to bounce back if it ever is.
Cybersecurity is getting crazy. AI, automation and cryptocurrencies have combined to reduce the size a business needs to be in order to be profitable to attack.
Generally the attack takes the form of ransomware. Attackers find a way to isolate important databases or file stores and encrypt them. Make a transfer of a large sum of Monero to a drop wallet and they will decrypt it for you.
For almost all businesses their databases and file stores are in the cloud, protected by the large dedicated security teams of Amazon, CloudFlare, Google, Microsoft, etc. This means the weakest link is the access to those databases and file stores.
Your business premises and your staff are the hackers’ easiest avenue to gain access, so that’s where they focus their efforts and that’s why you require a multi-layer security strategy for protection.
Not everyone can afford a full-time security team or coverage from enterprise security vendors, but everyone can implement the basic must-haves for cybersecurity to reduce their risk while they find a cyber insurance provider.
What follows is a standard layered approach to security, starting with internet access and ending with your staff’s minds. If you’re missing any of these, make it a priority to put them in place.
Secure The Network Perimeter
Your connection to the internet. What traffic is coming and what traffic is getting out.
What you need to do: Install a Network Firewall.
In this day and age we all know what a firewall is, right? Most modem/routers have a basic one. It will block automated vulnerability scans and other network attack vectors from the outside, and give you control over how machines inside your network can access external services. Handy if a machine does get compromised.
Business-grade routers with integrated firewall capabilities are available from vendors such as Ubiquiti (UniFi Security Gateway) , or entry-level appliances from security-focused vendors like Fortinet (FortiGate) and Sophos (XG Firewall)
Secure Your Local Network Access
This layer concerns how users and devices connect to your internal network, primarily via Wi-Fi.
What you need to do: Implement Secure Wireless Network Configurations.
This is straightforward:
- use WPA3 (or at least WPA2-AES) encryption,
- disable WiFi Protected Setup (WPS),
- change the default administrator password, and
- implement a separate, isolated guest WiFi network
Most business-grade Wi-Fi access points and routers from vendors like Ubiquiti, Cisco, TP-Link (Omada series), and Netgear (Business series) support these features.
Secure Your Devices and Software
This is the desktop/laptop/phone layer. Because these are complicated and vulnerable out of the box there are 6 things you need to do to secure these “endpoints”.
1. Keep Software Updated
Turn on automatic updates on all your machines and leave it on. Yes, it will occasionally be annoying as an update occurs when you have better things to do, but those annoyances will never add up to the amount of time and money a cyber attack will cost.
Microsoft has Windows Update for Business for OS updates. Microsoft Intune can provide more comprehensive update management across devices and some third-party applications.
Apple sends out security updates regularly. You can set your Apple devices to automatically apply security updates while keeping OS updates manual
2. Use Endpoint Protection Software.
This is your virus scanner/malware detector like CrowdStrike Falcon. You run these because vulnerabilities (“0-days”) can happen at any time and who knows if visiting a website or opening an email has compromised a machine.
Endpoint protection software notices when file or network requests suddenly appear from a new program or an existing program seems to be behaving differently, likely trying to scan ports on other machines in the network.
They do create processing overhead and their scanning can get in the way, but what can you do? Leave yourself wide open?
Windows has Microsoft Defender (built into Windows), with additional threat and management capabilities in its Microsoft Defender for Business. There are also third party solutions such as ESET Endpoint Security, Trend Micro Apex One, Sophos Intercept X, and, as mentioned earlier because of its famous fumble, CrowdStrike Falcon.
3. Enable Per-device Firewalls.
This helps in the situation where you end up with a compromised device on your network. There is probably no good reason for Machine A to be connecting to Machine B on your intranet. All shared resources are in the cloud, right?
Using an on-device firewall to block traffic from local machines, and also report when blocking events occur, protects your intranet from a compromise spreading.
Firewalls are part of most endpoint security suites, and Microsoft Defender also offers basic firewall functionality.
4. Use device encryption, at the very least on laptops
It is unlikely a “hacker” will break into your business to steal a computer with data on it. If you face that level of threat you’re probably not even reading this article.
Laptops, being out in the world, have a higher chance of being stolen. They can also be accidentally left behind.
Encrypting hard drives so that the data can’t be read without a password or key is the solution to this.
Microsoft has BitLocker Drive Encryption for this, and recovery keys can be managed via Microsoft Intune if you’re worried about getting locked out. Apple has FileVault for hard drive encryption, while Google’s ChromeOS devices are encrypted by default.
5. Enforce the Principle of Least Privilege
This is simply granting users only the minimum system permissions they need to fulfil their role functions on the machine(s) they use.
The basic move is not giving admin accounts to users. If they don’t have full access over the machine, any code run during one of their sessions doesn’t have full access either. This limits the damage that a compromised account can cause.
6. Establish Basic Mobile Device Security for Accessing Company Data
This is for phones and tablets, whether they’re company-owned or personal (BYOD). It means making sure everyone is using strong passcodes or biometric authentication, device operating systems are kept up-to-date, application installs are monitored, and a VPN is used when connecting to public Wi-Fi networks.
All major providers offer Mobile Device Management (MDM) and Mobile Application Management (MAM) solutions. Here are links to Apple, Microsoft, and Google MDM solutions.
Secure Access to Applications and Services
This layer focuses on how users access your business applications and cloud services, and that is via passwords. Passwords scribbled on post-it notes are not going to work in a team environment, plus you can’t copy and paste (yeah, yeah, you can with your phone…).
What you need to do: Implement password managers and add multi-factor authentication.
For password managers, it’s straightforward:
- Deploy a team-based password manager solution across your business
- Mandate its use across all services
- Share credentials securely between team members when needed
- Ensure employees can access passwords across all their devices
For multi-factor authentication (MFA):
- Enable it everywhere you can, but especially for cloud providers, email and financial applications
- Only use authenticator apps or security keys.
- Never use MFA via SMS.
- Make it mandatory for all users
Team-based solutions include 1Password Business and Bitwarden Teams. For MFA, Google and Microsoft have apps plus Microsoft offers Microsoft Entra multifactor authentication with their Microsoft 365 plans.
Strengthen Your Human Defenses
This layer acknowledges that your employees play a key role in how secure your business is. You might think you can’t install software on them, but that’s exactly what training does.
Most of the threats are going to come in via email, but in this age of easy deepfakes, phone calls and video calls are also vectors.
What you need to do: Train your staff and protect your email.
For training:
- Run regular cybersecurity awareness sessions
- Teach employees to recognise phishing and social engineering attempts
- Create a culture where reporting suspicious activities is encouraged
- Consider establishing verification pass phrases that employees can use to confirm identities during calls if security or finances are involved. So old-fashioned. But it’s also our future.
For email protection, the major providers, Microsoft and Google, actively scan all email, but they can’t catch everything. But that’s why you have endpoint protection in place.
Protection and Recovery of Business Data
This layer ensures your essential data stays safe and can be restored if needed. You need backups. You need proof you can restore from those backups in a reasonable amount of time at any moment.
What you need to do: Set up regular backups, practice restoring
For backups:
- Follow the 3-2-1 rule: three copies, two different storage types, one off-site
- Test your backups regularly to make sure they can be restored
- Keep backups separate from your main network to protect from ransomware
- Make sure all your backup systems are protected by MFA.
Microsoft offers Microsoft 365 Backup and Purview Data Loss Prevention. Google provides Data Loss Prevention for Google Workspace. For comprehensive backup solutions, consider Veeam Backup or Backblaze Business Backup.
Establish Basic Security Governance and Response
This layer involves having plans in place for possible incidents. If your security does fail, you want to be able to move quickly and minimise disruptions,
What you need to do: Create and document your incident response plan.
For incident response:
- Create a plan for what to do when security incidents occur
- Identify key contacts and detail the steps to take
- Practice the plan occasionally (even just a quarterly walk through around a table) so everyone knows their role
Microsoft provides security guidance documentation and Purview Compliance Manager. Google offers best practice security recommendations for Google Workspace.
Security is a lot, isn’t it?
This “basic” list probably already feels overwhelming. You may have simply scrolled all the way down here just to see if it was really worth reading.
It is a long list, but if you look through it, mainly it is about making a decision and implementing it. Then it’s just monitoring and checking in on it every quarter. And never trusting an email or incoming Zoom call ever again.
Because keeping your business safe requires constant vigilance and the software tools to enhance it.
A Hack to Reduce Your Developers’ Admin Using AI Coding AssistantsIt’s well known that a surprisingly small portion of a developer’s work week is dedicated coding. Big chunks of their time is dedicated to administrative tasks like refining user stories, managing epics, detailing acceptance criteria, and all the other work that happens around the coding.
This administrative load reduces the time available for core development work, limiting how fast your team can move.
However, the same models that power AI coding assistants like Cursor, GitHub Copilot, and Windsurf AI are the same models you use in Claude or ChatGPT or Google Gemini.
This means the AI coding assistants can be used for more than just writing code.
By employing the right tooling and practices, AI can potentially cut down the time spent on writing, reviewing, and synchronising epics, stories, and acceptance criteria by a significant margin.
Leveraging AI for More Than Code
AI coding assistants can be used to reduce the administrative overhead that consumes developers’ time without requiring them to swap to a different app or a browser.
It can all be done directly within the IDE. Cursor and Windsurf AI allow developers to create “rules” – documents that instruct the AI on how to complete specific tasks. While they were intended to provide task-dependent context and guidance to the coding assistant, these rules can also be used to provide context and guidance in generating drafts and revisions of project and sprint documentation, user stories, and other essential agile artefacts.
Streamlining Workflows with MCP and Project Management Integration
The coding agents within these AI-powered IDEs can also be connected to popular project management tools like Jira and Linear through the Model Context Protocol (MCP).
MCP is an open standard designed to enable two-way communication between AI applications and external data sources or tools. This protocol allows AI assistants to pull information from these project management systems and even push updates like new tickets or status changes, further automating administrative tasks.
This integration means that an AI assistant, guided by predefined rules and connected via MCP, can:
- Draft a user story based on a brief description.
- Populate relevant fields in a Jira or Linear ticket.
- Update the status of tasks based on development progress.
- Flag inconsistencies or dependencies between different user stories or epics.
Example: Cursor Rule for Drafting a User Story
AI coding assistants like Cursor use rule files (for Cursor, .mdc files in a .cursor/rules directory, where .mdc is just Markdown with Cursor-specific metadata in the header) to guide the AI’s behaviour. These rules can define the AI’s persona, its understanding of project-specific conventions, and the desired output format for various tasks.
Here’s a very short, conceptual example of what a Cursor rule file for drafting a user story might look like:
--- description: "User Story Generation Rule" globs: alwaysApply: false ---
You are an expert Agile Business Analyst. Your role is to help draft clear, concise, and actionable user stories. ### User Story Structure: When asked to draft a user story, follow this format: **As a** [type of user], **I want to** [perform an action], **So that** [I can achieve a goal/benefit].
### Clarification: If the request to draft a user story does not include details about the user or action or benefit stop and ask for clarification on the user type, desired action, or intended benefit before drafting the story. Only the user can decide what the user story is about.
### Acceptance Criteria: For each user story, also draft a preliminary list of acceptance criteria. Start with at least three criteria. - Acceptance Criterion 1: - Acceptance Criterion 2: - Acceptance Criterion 3: ### Task Generation: Suggest 2-3 initial development tasks that would be required to implement this user story. - Task 1: - Task 2: ### Final Step:
Follow the user's instructions for any requested changes. After each change ask the user if the User Story is complete. If they confirm it is complete, use the Jira MCP server to add the User Story to the current project.
This rules file instructs the AI on the standard user story format, the need for acceptance criteria and related tasks. It has a final step that instructs the AI to use a Jira tool to add the created user story to the current project.
It doesn’t make up the User Story itself. That thinking still needs to be done by the developer who understands the broader context of the project beyond the code. It does however, rely on the AI to generate initial acceptance criteria and tasks. How well these will match your developers’ intentions depends on how well represented your product is in the AI’s training data.
Now, this rules file is just a draft. It will need tweaks to work consistently in your codebase. Use it more as a source of inspiration. What other steps in your process can you automate or streamline using the AI in your team’s coding assistant? And don’t forget that you can use the AI coding assistant to write the rules files for you.
Remember: Your Coding Assistant is an Everything Assistant
For now, the AI under the hood of your coding assistant is a SOTA frontier model that can do more than just code. With the right rules files and attached to the right MCP servers, your coding assistant can do everything any other AI tool can do. All from the one interface. Make the most of it to accelerate your team.
5 Platforms For Optimising Your Agents ComparedSo, you’re looking at building Large Language Model (LLM) agents. With the recent increases in model capability at all sizes, and the feature-rich frameworks available (like LangChain, LlamaIndex, AutoGen, CrewAI, etc.), getting agents up and running is easier than ever.
However, there’s a significant jump from an initial functional prototype to a system that’s reliable, performs consistently well, and executes affordably when running in production.
It turns out, building the agent is the easy part. Making it truly performant is where the real challenges lie.
This article dives into that gap. We’ll look at the common hurdles faced when taking LLM agents into production and explore the essential tools and capabilities needed to overcome them.
Let’s get into it.
Why Agent Performance is Hard
Transitioning an LLM agent from a proof-of-concept to production-ready means tracking and addressing reliability, consistency, cost, and overall quality. Here are some of the key challenges:
- Hallucinations & Accuracy: hallucination poses a significant risk, especially if your application needs high precision. Ensuring factual consistency is crucial but surprisingly hard to guarantee consistently.
- Latency & Scalability: Users expect reasonably fast responses. Agents, particularly those running complex reasoning chains or calling multiple external tools, need to deliver results within acceptable timeframes, even when usage ramps up. A prototype that works fine with a few test requests might be too slow under real production load, or scaling it might become prohibitively expensive.
- Cost Management: LLMs are accessed via APIs charging per token (input and output). These costs can vary based on model, context size, caching and inference provider. You need ways to track costs granularly – maybe per user, per feature, or per agent run – but this often requires specific tooling.
- Prompt Brittleness & Engineering: Getting prompts right is more art than science sometimes. Crafting prompts that consistently guide the LLM to the desired behaviour is an iterative and often difficult process. Keeping these prompts effective as models update or requirements shift adds another layer of maintenance overhead.
- Context Window Limitations: LLMs can only “remember” a certain amount of information from the current interaction (their context window). In long conversations or complex tasks requiring information recall over many steps, they can forget earlier instructions or details, limiting their effectiveness. A long context window that might make an agent performant, will also make it more expensive to run.
- Complex Planning & Error Handling: Agents can struggle with tasks needing sophisticated multi-step planning. If an Agent can get each step right 90% of the time, if your process has 6 steps you’ll get a successful result only 60% of the time.
- Data Quality & Bias: The agent’s output is heavily influenced by its training data and any data you feed it at runtime (e.g., via Retrieval-Augmented Generation – RAG). If that data is poorly structured, incomplete, or biased, you risk getting inaccurate results.
- Security & Privacy: Integrating LLM agents brings security considerations. Think about potential data leaks, prompt injection attacks (where users trick the agent with malicious input), and the need to handle sensitive user data securely and comply with regulations like GDPR.
These aren’t just theoretical concerns. Companies like Acxiom, for example, faced difficulties debugging complex multi-agent setups and found they needed platforms like LangSmith to get the visibility required for optimisation and cost management. Research from Anthropic also suggests that simpler, more composable agent designs often prove more successful than highly complex, monolithic ones, highlighting that managing complexity itself is a major challenge. In Acxiom’s case, they were working with 60 LLM calls and over 200k tokens of context to answer a client request.
The challenges in building on top of LLMs are interconnected. Making a prompt more complex to improve accuracy will increase token count, cost, and latency. Simplifying logic to reduce latency might increase errors. Optimisation becomes a balancing act. This is where dedicated tooling becomes essential and you need to move beyond the basics of looking at logs and monitoring API call rates to true observability.
While monitoring tracks known metrics (errors, uptime), observability gives you the tools to understand why your system behaves the way it does, especially when things go wrong unexpectedly. Given the non-deterministic nature and potential for novel failure modes in LLMs, observability is critical for diagnosing issues that simple monitoring might miss.
Key Capabilities for Managing LLM Agents
Observability and evaluation platforms offer a suite of core capabilities designed to help you manage the performance, cost, and reliability of LLM agents.
Each platform has its own strengths and weaknesses, but they all offer variations on the same functionality:
- Monitoring & Tracing: This is foundational. It means capturing detailed records of everything your agent does – tracing the entire execution flow of a request, logging inputs, outputs, intermediate steps (like tool calls), latency for each step, cost, and any errors. Good platforms visualise these traces, making complex workflows easier to understand. For development teams, this detailed tracing is invaluable for debugging. You can quickly find latency bottlenecks, pinpoint where errors occurred in a chain, and see exactly how the agent produced a specific output, saving hours of diagnostic time.
- Cost Tracking & Analysis: With token-based pricing being common, keeping costs under control is vital. These platforms monitor token usage (prompts and completions), calculate costs per API call or session, and let you slice and dice cost data by user, feature, model, etc. Dashboards help spot trends, identify cost spikes, and find optimisation opportunities (like do you try using cheaper models for certain tasks).
- Experimentation & Evaluation: Improving agent performance requires systematic experimentation. Platforms facilitate this with features like A/B testing (comparing prompts, models, parameters side-by-side), automated quality metrics (like BLEU, ROUGE, BERTScore), workflows for collecting human feedback, using another LLM to evaluate outputs (“LLM-as-a-Judge”), and interactive “playgrounds” for quick prompt testing. These tools allow teams to take a data-driven approach, test hypotheses rigorously, validate changes before deploying them, measure performance against benchmarks, and continuously refine agent quality.
- Dataset Management: Good evaluation needs good data. Platforms often include tools to create, manage, and version datasets specifically for evaluating agent performance or even fine-tuning. You might import existing data, generate synthetic data, or – very usefully – create evaluation datasets directly from problematic production traces you identified via monitoring. This lets you build targeted tests based on real-world failures, ensuring your fixes address actual issues.
- Prompt Management (CMS): Prompts are central to agent behavior, but managing them can get messy. Many platforms now offer Prompt Management features, acting like a Content Management System (CMS) for your prompts. This typically includes a central registry, version control, collaboration features, and integrated testing. A key benefit for many teams is the ability to update and deploy prompt changes directly from the platform’s UI, without needing a full application code change or redeployment. This dramatically speeds up the iteration cycle for prompt engineering and can even allow non-technical domain experts to contribute to prompt refinement.
The real value comes from how these capabilities integrate. You might use monitoring to spot a pattern of poor responses, use those traces to create an evaluation dataset, test a new prompt against that dataset using experimentation tools, deploy the winning prompt via the prompt management UI, and then monitor its impact on performance and cost – all within the same platform. This integrated feedback loop is key for continuous improvement.
Of course, platforms vary. Some excel at deep tracing, others have prompt management UIs to allow non-developers to contribute, some come from a broader MLOps background with deep evaluation features, and others focus on simplicity and cost-effectiveness. This means you need to consider your specific needs when choosing.
5 Platforms For Agent Optimisation
Let’s look briefly at five platforms offering relevant observability and evaluation capabilities: Langsmith, Helicone, Weights & Biases (W&B) Weave, Langfuse, and PromptLayer.
Langsmith
Developed by the LangChain team, Langsmith integrates very tightly with the LangChain/LangGraph ecosystem. Its strengths are detailed tracing, debugging, evaluation, and monitoring, especially for complex chains built with LangChain (their core framework available in Python and JavaScript).
It’s a solid choice if your team is heavily invested in LangChain. It offers debugging traces, monitoring dashboards, cost tracking (per trace), a testing/evaluation framework with UI configuration, dataset management (including creation from traces), and a “Prompt Hub” for UI-based prompt management and deployment.
Integration is trivial for LangChain users. Pricing includes a free developer tier and paid plans ($39/user/mo Plus) suitable for small teams, with usage-based costs for extra traces.
Helicone
Helicone positions itself as an open-source observability platform focused on ease of use and cost management. Its standout features are super-simple integration (often just a one-line change via a proxy for your inference provider’s API), strong cost tracking (per user/model, caching), and flexibility (self-hosted or cloud).
It’s great if you prioritise rapid setup, tight cost control, or open-source. It monitors core metrics (latency, usage, cost, TTFT), supports prompt experiments/evaluations (including LLM-as-a-judge via UI), dataset curation, and UI-based prompt editing, versioning and deployment.
Integration via proxy is very fast; SDKs are also available. Pricing is attractive, with a generous free tier, a Pro plan ($20/seat/mo + add-ons for prompt/eval), and a cost-effective Team plan bundling features. The open-source self-hosting option offers maximum control.
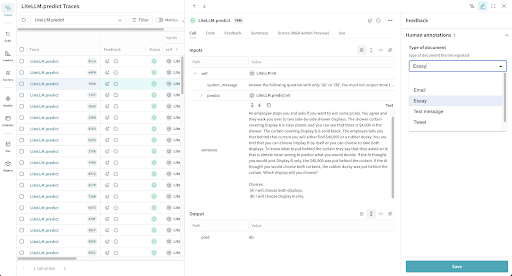
Weights & Biases (W&B) Weave
Weave is the LLM component of the established W&B MLOps platform. It leverages W&B’s strengths in experiment tracking, model versioning, and dataset management, extending them to LLMs. It emphasises rigorous evaluation and reproducibility. Best suited for data science/ML teams, especially those already using W&B, needing sophisticated evaluation and MLOps integration.
It offers tracing linked to experiments, cost tracking, a powerful evaluation framework (pipelines, scorers, RAG eval), robust dataset management integrated with evaluation, and SDK/API integrations.
Pricing includes a limited free tier and a Pro plan ($50/mo+) with usage-based costs for data ingestion.
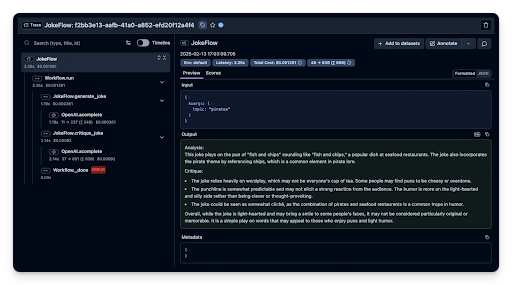
Langfuse
Langfuse is another prominent open-source LLM engineering platform (often seen as a Langsmith alternative) offering tracing, analytics, prompt management, and evaluation.
It appeals to teams wanting open-source flexibility, self-hosting, or broad framework support beyond LangChain.
It provides deep tracing (visualised), session/user tracking, cost tracking, extensive evaluation features (datasets from traces, custom scoring, annotation queues), dataset management, and broad SDK/integration support (including OpenTelemetry).
Its UI prompt management allows no-code deployment via labels (production/staging). Pricing is SME-friendly: a generous free cloud tier, affordable Core ($59/mo) and Pro cloud plans, and the FOSS self-hosting option.
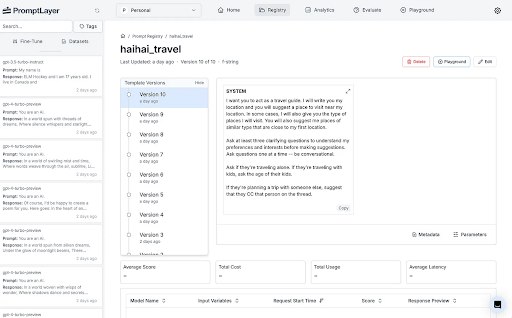
PromptLayer
PromptLayer focuses heavily on the prompt engineering lifecycle: management, versioning, testing, collaboration, and observability, with a strong emphasis on visual tooling (no-code prompt editor, visual workflow builder). Ideal for teams needing rapid prompt iteration, cross-functional collaboration (engineers, PMs, content specialists), and visual development.
It offers request logging, performance dashboards, cost tracking, prompt-centric experimentation (A/B testing, backtesting, human/AI grading), and SDK/API integrations.
Its core strength is the “Prompt Registry” – a visual CMS allowing no-code prompt editing, versioning, and importantly, UI-driven deployment decoupled from code releases. Pricing includes a limited free tier and a Pro plan ($50/user/mo) with a high request limit.
Comparing The Platforms
| Feature | Langsmith | Helicone | W&B Weave | Langfuse | PromptLayer |
|---|---|---|---|---|---|
| Ease of Integration | SDK | Proxy/SDK | SDK | Proxy/SDK | SDK |
| Monitoring Depth (Tracing) | High | Medium/High | High | High | Medium |
| Cost Tracking Granularity | Medium | High | High | High | High |
| Experimentation/Eval | High | Medium/High | Very High | Very High | High |
| Dataset Management | High | Medium | High | High | Medium |
| UI Prompt Mgmt (No-Code) | Yes | Yes | Unclear/Likely No | Yes | Yes (Core Strength) |
| Open Source Option | No | Yes | Yes | Yes | No |
| Key Strengths | LangChain integration; Balanced | Ease of integration; Cost control; Open Source | Robust evaluation; MLOps integration | Open Source; UI Prompt Mgmt; Balanced | UI Prompt Mgmt; Visual workflows |
Selecting the right platform involves weighing features, integration effort, cost, and how well it fits your team’s specific situation. Here are some key trade-offs you will want to consider:
- Open Source vs. Closed Source: Helicone and Langfuse offer open-source versions. This gives you potential cost savings via self-hosting, more data control, and avoids vendor lock-in. The trade-off is the technical overhead of setting up, maintaining, and scaling it yourself. Closed-source, managed cloud options (Langsmith, W&B Weave, PromptLayer) offer convenience and support but come with subscription fees and less control. You need to balance the desire for control/savings against operational resources.
- Ease of Integration: How quickly can you get value? Helicone’s proxy approach is near-instant. Langsmith is very easy if you’re already using LangChain. SDK-based integrations (common to most) require more code but offer flexibility. OpenTelemetry support provides standardisation but involves its own setup. Consider your team’s skills and how fast you need to get observability in place.
- Breadth vs. Depth: W&B Weave offers the broadest scope, embedding LLM observability within a full MLOps platform – powerful, but maybe overkill if you only need LLM tooling. PromptLayer goes deep on prompt management and visual workflows, perhaps with less emphasis on deep tracing than others. Langsmith and Langfuse offer a strong balance across tracing, evaluation, and prompt management. Helicone focuses tightly on core observability, cost, and ease of use. Identify your biggest pain point (debugging? prompt iteration speed? evaluation rigor? cost?) and align the platform’s focus accordingly.
- Pricing Models: Understand the costs. Per-user models are predictable by team size but can get pricey. Usage-based components (traces, requests, events, data ingestion) need careful estimation – W&B Weave’s ingestion cost, in particular, can be hard to predict. Free tiers are great for trials but often have limitations (users, retention) making them unsuitable for full production. Model your expected usage to compare the total cost of ownership (TCO).
- UI Prompt Management: The ability to manage and deploy prompts via a UI without code changes is a major accelerator for iteration and collaboration. Langfuse, PromptLayer, Helicone, and Langsmith provide this clearly. If rapid prompt iteration involving non-engineers is key, prioritise platforms strong in this area.
Ultimately, there’s no single “best” platform. The optimal choice depends heavily on your context: your main challenges, budget, team skills, existing tools (especially LangChain), and the strategic importance you place on features like open-source or UI-driven prompt deployment.
Get Your Agents Production-Ready
Developing and deploying LLM agents can feel like two different worlds: the initial build can feel straightforward, but achieving consistent, reliable, and cost-effective performance in production is a complex engineering challenge.
But that challenge can be navigated with the right platform. Find the one that fits your needs, integrate it into your process, and you can start optimising your Agents today.