One of the major challenges in the transition to agentic coding is being able to tell if the usage of these techniques is ROI positive. And in an environment where each new model release comes with higher token costs, and an industry claiming we are heading towards a compute crunch, having a clear insight into the costs of agentic coding is necessary. Uber famously spent their annual AI budget in months and had to set limits.
The problem is that no-one currently provides a turnkey solution that lets you say “Here is the feature, and here is what agents cost us to build it”. But most of the pieces to do that are already in place, and depending on how your developers work, there might be a path to building (or getting agents to build) that reporting.
We’re not going to show you how to build such a system, but we are going to give you a quick overview of what’s available and links to more detailed information and guides that you, or your agents, can use.
And we’re going to start with the problem.
The problem of AI attribution
There are two reasons you can’t currently answer “what did that feature cost?”.
Subscriptions are opaque already, but once you’re past a few seats, you pay per token. Anthropic’s Enterprise plan meters every token on top of the seat fee, and OpenAI and GitHub have moved the same way. GitHub shifted every Copilot plan onto usage-based billing in June 2026. The flat subscription is on its way out.
The second is that the providers don’t tell you the cost. When a tool calls a model, the response reports the number of tokens used, not a dollar figure. You have to multiply those token counts by the current price list yourself. The exception is OpenRouter, which sits in front of the models and returns the actual cost on each call, but their services charges a fee of around 5% of your token spend.
So your monthly total is easy to find, but the cost of a single feature or bug fix is not. No mainstream tool joins spend to a unit of work today.
Without a per-unit cost you can’t work out your ROI, you can’t price a feature or settle a build-versus-buy question on real numbers.
What you need is two things for each piece of work: what it cost, and what it was for. You capture both when the agent runs, then join them afterwards. How far you can take that depends on where your developers work.
Cost attribution depends on where your developers work
Whether the money leaves through a terminal, an IDE, or your own code decides how precise your answer can be.
Terminal agents
If your developers use a terminal-based agent like Claude Code, OpenAI Codex, Amp, pi, etc, you have the most room to move. These tools let you set the endpoint they call, so you can send every request through a gateway that sits between the agent and the model and prices each call and records whatever label you attach. LiteLLM, Helicone and Cloudflare AI Gateway all do this, and the first two you can host yourself.
LiteLLM is the closest thing to an off-the-shelf answer. You point the agent at it and pass a customer id or a tag on each request, and it prices the call and files it under that tag. There is a walkthrough for doing exactly this with Claude Code.
Helicone works the same way, and lets you segment cost by custom properties you set on each request, so your branch or ticket becomes a filter in its dashboard.
Cloudflare AI Gateway is the managed option if you would rather not run anything. It logs the cost of every request and lets you filter on it, though you get less control over the labels than with the other two.
If your team uses Claude Code, you don’t need a gateway at all. It can export its usage over OpenTelemetry, an open standard for emitting metrics that dashboards can read, and it will attach whatever labels you give it to each cost figure. That is the simplest way to get a labelled, priced record without adding a service to the path, and if you want a running start there is an open-source setup, claude-code-otel, that wires the export into ready-made dashboards.
IDEs: Copilot, Cursor, VS Code
Inside an IDE, how much you get back depends on the editor and, more than anything, on whose models you are paying for.
GitHub Copilot has two modes here. Run it on GitHub’s own models and you get spend per user, per day and nothing finer, with the pull requests its agent opens folded into that daily figure. But Copilot also lets you bring your own provider key or a custom endpoint, and once you do, the spend leaves GitHub’s meter and lands on your provider account, or on a gateway you point it at. That puts you back in the terminal case, with a priced, labelled record per call.
Cursor keeps you on its own billing for agent work, so you are limited to what its APIs expose. Its Admin API reports cost per request, and its AI Code Tracking maps AI-written lines to the commit they landed in. The two sit apart, though. Nothing shared joins a dollar amount to a given commit or pull request, so a per-feature figure still has to be stitched together by hand.
VS Code gives you the most direct way to do the Copilot trick above. It has a setting to point it at your own model endpoint, which you can aim at one of the gateways from the terminal section.
Your own harness
If your team has built its own harness around the models, this is straightforward. You own the call, so you record the cost and the label together. It is one reason teams that care about attribution keep a thin harness of their own.
Labelling the work
A number on its own isn’t much use until you attach a label to it: a branch, a ticket, a pull request, a developer, whichever unit your team works in. If you ship a feature per branch, use the branch. If you run everything through Jira, use the ticket. Match it to how your team already divides the work.
Both of the mechanisms above take a label. A gateway reads it from a header on the request, and Claude Code’s telemetry takes it as an attribute you set before the run. So the practical trick is a one-line wrapper around the command your developers already use to start the agent. It reads the current git branch and sets that header or attribute for them. Nobody has to remember to tag anything, and the branch ends up on every cost record, ready to join to a pull request and a ticket later.
It doesn’t change how your developers work, which is the point.
How far do you need to go
There are three levels, and the right one depends on what your team will actually keep running.
The cheapest is an estimate. You divide your total AI spend by the number of pull requests you merged and call it a rough cost per PR. That is what DX’s AI cost report gives you: a useful trend line, and an average that tells you nothing about any particular feature.
Building it yourself is the only route to a real per-feature number. You carry the label with the spend using the pieces above, then join branch to pull request in your own database. It is a couple of hundred lines of work, and no-one sells it as a product yet.
Buying help gets you part of the way. Engineering-intelligence vendors like Faros will pull your AI spend together and attribute it by team, tool and type of work, which is enough for budgeting and for seeing where the money goes. What they won’t hand you is a dollar figure against a single feature or pull request.
No tool will point at a feature and tell you what it cost. What you can do is decide how close you need to get, and pick the level of effort that matches.
Is AI cost attribution worth doing?
Before your team builds anything, you need task yourself three questions.
What would you do differently if you knew the cost of a feature? If the answer is nothing, leave it, keep an eye on the monthly total and keep doing what you’re doing.
Where do your developers work? That decides what your options for AI cost tracking and your accuracy before you start.
And how accurate does that number actually need to be? For a rough sense of it, count your merged pull requests and divide your AI spend by them. Stick the numbers in a spreadsheet and after a few months you will be able spot the trend, but not learn anything about a particular feature. For a cost you can put against an actual feature, you are into the small build of your own from the last section. Do whichever is worth your while.
The cost attribution gap is real, but we expect it to be temporary. Vendors will close it in time. Until they do, the teams that get useful numbers are the ones that put basic tracking in place: tagging the work, logging the spend, and integrating the numbers into reporting and decision making.
What Is Loop Engineering And Why Should You Care
Remember a long time ago (2024) when prompt engineering was the frontier of AI and people were landing 6 figure roles to engineer prompts? Prompt engineering was followed by context engineering, and that by harness engineering. The gap between each “engineering” growing shorter each time.
The latest engineering causing the tech internet to lose its mind is loop engineering. The mind-losing was triggered by this tweet from OpenClaw creator Peter Steinberger:
In an industry already dealing with the fallout of having machines do the very thing that was the core of their career and for many the soul of their identity, implying everyone should get over unanswered questions on the quality of AI-generated code and move on to embrace these vague “loops” created panic in everyone who didn’t know what these “loops” were and friction between the code purists and the agent maximalists.
It also amplified the anxiety over the increasing costs of agentic coding. Peter Steinberger works for OpenAI and posts about burning through billions of tokens a month. The other headliner talking about loops was Boris Cherny, head of Claude Code at Anthropic. He has said in interviews “my job is to write loops”. He also has access to unlimited tokens.
If loops were where the future of agentic coding was heading, who could afford to follow? And the silent corollary – if you can’t follow how can you compete?
So, we’re going to give a quick breakdown of what loop engineering is and some examples of how and where it can be used. As for affording to follow – that’s a bit of a case-by-case $$$ vs infrastructure questions which we will touch on briefly at the end.
What is loop engineering
Loop engineering is automation that relies on the judgment and abilities of agents. Judgement here includes how to do a task/solve a problem, if a solution is correct, and if the result needs to be escalated to a human.
This opens up a whole new universe of possibilities that deterministic, software-based automation can never touch.
At its most basic level it is an orchestration pattern that combines:
-
Scheduled or triggered execution
-
Isolate workspaces – so agents don’t overwrite other agents’ work (because you will of course be running hundreds of agents in parallel)
-
Verification – this is the key to making loops viable: provable success
-
Persistent memory – this could be an issue tracker or a database
Verification falls into two categories – deterministic and agent-based. Deterministic verification is things like build systems, linters, benchmarks, test suites – code that runs and returns actionable information: errors that need to be corrected, numbers that aren’t low enough/high enough yet. Agent-based metrics leverage the judgement of agents to verify that outputs meet complex or subtle criteria, or criteria that the developer can’t be bothered building into deterministic verification steps.
Agent-based verification works best if a separate agent with no shared context, and preferably from a different model family, is used. So use GPT-5.5 to judge the outputs of Opus 4.8 and vice versa. This is used particularly for coding oriented loops where what is being verified is complex in itself.
What loop engineering is used for
The success of AI-based coding is due to the simple fact that solutions to coding problems can be tested and verified, making training and improvement in the domain possible. This extends to the kinds of “loops” that can be engineered.
These examples have been collected and summarised from discussions across the tech internet. They are broad and they are not exhaustive.
Improving code quality
Set agents to work on (a copy of) your codebase with a simple goal like “simplify the code” or, more specifically:
“Reduce the cyclomatic complexity of the code while maintaining correctness. Run the test suite after each change and fix any errors that are reported. Keep going until you’ve revised every source file.”
Performance optimisation
This is much the same as improving code quality, but instead of your own test suite you might have an industry or inhouse benchmark that you want to impove on.
Processing logs
“Logs” here can mean anything from server logs to mailboxes. This is where a scheduled job might kick off at 7am every morning to go through each item and triage them.
For example, your product’s CI failures from the day before – you can a set a sub-agent per failure to work on a fix in its own worktree, then have a second sub-agent follow it up with a code review and running it against your product’s test suite. Perhaps a second round of failures at this stage results in it being elevated to a human.
Keeping documentation up to date
Every day, or every hour, you can have agents go through your codebase, or pull information from your CMS or a projects directory or whatever set of documents you need to have correct and current information available to your organisation.
The agents make sure sources and documents are in sync and all the information is structured, formatted and styled to match your inhouse standards.
Other loop ideas
People are out there trying to find where they can leverage loops for their own work. You can find a collection of sometimes quite specific loops at this site.
Don’t be surprised if it feels like prompt engineering all over again.
How to build loops
Tools for building loops are already present in the Anthropic’s Claude Code tool and in OpenAI’s Codex App (not to be mistaken for OpenAI’s Codex cli tool).
Claude is ahead here at the moment for ease of building loops.
Both have “/goal <condition>” (Anthropic / OpenAI) – tell the agent what you want to achieve and what success looks like and it will keep running until it reaches it, you stop it, or you exhaust your subscription, or your token credits (you did set limits on your billing, right?).
People have reported Opus and GPT-5.5 working over days to complete a goal successfully.
Claude also has “/loop <interval> <prompt>” command. It uses Anthropics scheduling infrastructure behind the scenes. Interval can be 5 minutes, it can be hours, and if you don’t suggest it, Claude will decide itself based on the prompt how often it should run.
You can also use Anthropic’s scheduling infrastructure directly via the “/schedule” command in Claude Code as well as in the Claude app.
OpenAI has automations available in the Codex app. You can prompt GPT-5.5 from a chat to set up schedules for any work you want to automate.
Of course, you can always write your own agent loops, or get the agents to write the loops for you.
The caveats of loop engineering
Infrastructure is infrastructure – it still needs to be created, documented and maintained. On top of that, loop engineering gives you the opportunity to wake up to immense invoices or at least exhausted subscriptions. There are ways around this.
We don’t just mean setting limits. We mean exploring alternative providers to OpenAI and Anthropic, if your product/vertical/nation allows it. The last few months have seen increasingly effective open weight models becoming available. They are much cheaper than Opus and GPT-5.5, and are being served by multiple neo-clouds, and available via OpenRouter.
Your entire loop doesn’t need to run on these models. You can have your Opus/GPT-5.5 agents delegate the legwork to agents running on these cheaper models. All it takes is a little more set up and a little more testing for permanent cost decreases.
And, if your organisation is technically proficient and likes a challenge, you can investigate running models locally for parts of your workflow. Agents promise to do a lot and they will do it by burning compute. So owning the compute and being able to burn tokens 24/7 to update that documentation, clean up that code, etc, might be what makes them viable for you.
The human cost of loop engineering
When you can launch hundreds of agents at the click of a mouse the human becomes the bottleneck and, because agents are imperfect and the world is messy so escalation to humans is common, the workload can become inhumane. And once the workload becomes more than what a person can diligently attend to, slop begins to accumulate, and once it accumulates it becomes load bearing.
So the only strategy here is to scale the number of agents to match the humane review rate. Scaling beyond this rate will lead to dropping standards, not to mention miserable team members looking for better options. And letting agents work ahead of reviews means burning tokens on code that suddenly needs to be rewritten because agents made and propagated mistakes or poor decisions about architecture.
Do you have loops worth engineering?
Loop engineering is really about asking two questions. The first is “Where are we wasting the time and intelligence of a human in X% of the cases?”. Do you need a human to implement and test a 15 line code fix? Do you need a human to triage emails?
The second question is “What automated improvements/optimisations will pay dividends for us?”.
Once you have answers to either of those questions, it is often just a matter of asking an agent to implement a prototype of the solution and growing from there.
You Won’t Be Killed by a Weekend SaaS Clone. Here’s Who You Need to WatchThe chart below provides a new take on the “SaaS-pocalypse” talk that has been happening recently. What the chart shows – an explosion in new apps occurring alongside no net increase in app usage. What the means for software-based businesses is what we will be discussing.
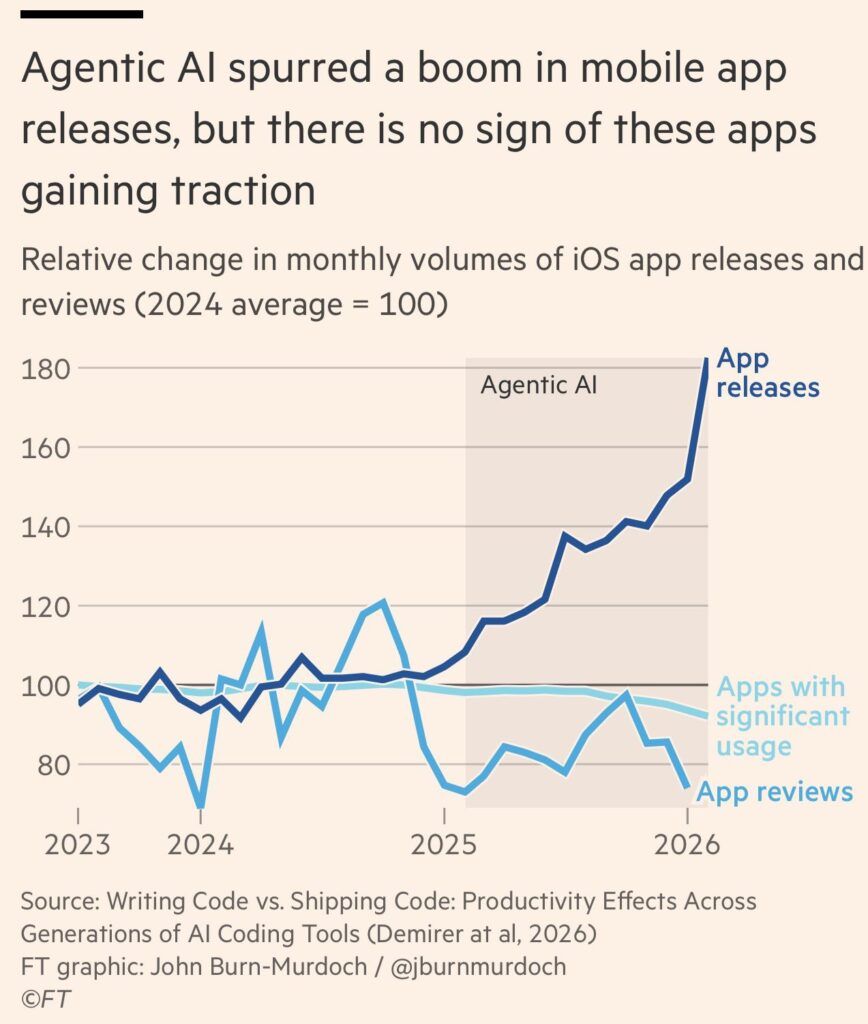
Where the chart comes from
The chart comes out of a study by MIT’s Mert Demirer (and co-authors): “Writing Code vs Shipping Code – Productivity Effects Across Generations of AI Coding Tools”. They used Github data to track the evolution of AI usage across lines of code written, number of files edited, the number of projects and features worked on and the actual releases of software.
This span of activities let them compare AI coding tools from first wave of auto-complete tools (eg Cursor and Github Copilot) through coding assistants to coding agents. What they found was that AI had increased productivity at the beginning of the process, with coders creating or editing 300% more files. But once they traced through the product development process to software releases, they found only a 30% increase.
The reason for this precipitous drop – humans in the loop. Amdahl’s Law says a system’s speed is constrained by its slowest step, and in the era of agentic coding we are responsible for all those slow steps. And it is likely that that for some software products, that rate of software releases may not increase much.
While line counts can increase at agentic speed, most processes in this world are still constrained by real world dynamics. You release features 30% faster, but your users aren’t moving 30% faster. Feedback trickles in, it’s contradictory, some users are seeing bugs. Whether or not the feature was a success will take time to resolve. And all the decisions that hang on that feature’s performance will have to wait.
These points where code meets the real, messy world are not going to go away and will continue to place an upper bound on how quickly we can progress.
And as that app chart shows, progressing quickly is not always progressing successfully.
The explosion of apps no-one wants
A common talking point that was part of the SaaS-pocalypse was that anyone could take your SaaS and reproduce it in a weekend. At the same time, “prompt an app” services like Bolt.new and Base44 promised product development for everyone. It did feel like the competition was going to rise to an unprecedented level.
But what has happened in the app stores is very different to the narrative. More apps than ever were created, but very few were being used. There are three broad explanations that alone and together might explain this: the apps work poorly (bad architecture), the apps look unappealing (bad design), no-one knows about them (bad marketing).
Another frequent talking point around the use of AI is “taste”. “Taste” is the knowledge and experience needed to extract professional results from what are supposed to be frontier-level intelligence models. If you don’t have a working knowledge of application architecture can you get AI to build you an app that can grow and improve while handling edge cases and increased traffic? If you don’t understand UX and UI how can you know if your app is well designed and easy to use to others? And if you don’t understand marketing, how do you think people find apps and are onboarded?
To the surprise of no-one, being able to prompt an app (and we’re including web-based services as well in this) is not the same as being be able to run a software-based business. The rush of new competitors into the market is mostly a temporary inconvenience, but other vectors of competition have intensified.
The competitors you need to worry about
For every 100 or 1000 new quick-and-dirty apps in a market there are going to be 2-3 apps built by very small teams who have built exactly the same app for an ex-employer in the past. These new agent-native teams have the ability to reach feature parity faster than bigger orgs with larger teams that haven’t fully integrated AI. They lack the incumbents’ customer relationships and vendor networks, but they can only gain and the customer count they need is much lower than everyone else’s.
The other competitor is the one that has gone all in on AI and is making it work. An example of this is Fin, which you once knew as Intercom. They changed names mid-May. Last June, Darragh Curran, CTO and Head of Engineering at Fin/Intercom announced a goal to 2x their productivity. In April 2026 he announced their success and gave an outline of how they did it. Yes, they are one of those notorious companies that burns through tokens.
Over 9 months Fin 3x-ed the number of PRs. This was their measure, number of PRs, which Curran admits is imperfect for many reasons but served them well.
That 3x, 300%, is 10 times larger than the MIT study’s 30% increase in PRs. But the MIT study was a survey across random Github projects. This was an R&D focused tech company with an explicit goal to pursue.
They succeeded through continuous iteration and experimentation. They settled on a single provider – Anthropic. They built company-wide infrastructure for sharing and automatically updating Claude Skills, so any improvements propagated throughout the ~500 member team. They worked out what they could safely automate away (eg PRs with less than 20 lines of code) and built the infrastructure to make it safe.
This increase in PRs now represents an increase in speed across the company. Their revenue growth is accelerating. And in terms of competition, Curran says:
“we are able to say yes much more frequently, which translates into deals closing that would have been blocked, or accounts churning because we can’t support their evolving needs”
This is an incumbent moving at AI-native speeds but with reputation and relationships on their side.
Where on the MIT study-Fin scale are you?
This article was a little unfair. It started out making you feel better about the increase in competition AI has created, and has now probably left you worried about your existing competitors.
But, as they used to say, forewarned is forearmed. At SoftwareSeni we are constantly exploring best practices in software development across dozens of projects and in every corner of our operation.
If you ever want to chat about what we’re learning or if you’re interested in extending your team with developers trained in AI-assisted coding and embedded in an organisation dedicated to doing quality work with AI, get in touch.
SaaS Are Moving to Usage-based Pricing to Survive AIThe rise of AI agents is shifting how software services are consumed and so it is also changing how they need to be priced.
The traditional seat-based model relies on a simple idea: one human user equals one license.
Seat-based pricing doesn’t make sense in an economy with a growing population of agents that work 24/7 and outnumber the customers that run them against your APIs. More and more companies are following Mintlify’s lead – moving away from seats to usage-based pricing.
Usage-based pricing is a challenge to bolt on to an existing product. So we’re going to give you a quick overview of what you’ll be looking at, starting with – does usage-based pricing even make sense for your product?
Does Usage-Based Pricing Even Make Sense for Your Product?
The first step in deciding if you’re going to move to usage-based pricing (UBP to save typing) is to look at your industry and your competitors. Is it already common? Are others making the shift? If they are, adopting a similar structure can help you remain competitive. If they’re not, you might have a strategic window to capture some market share if your UBP can give potential customers the cost flexibility and lower adoption costs then you’re competitors can.
Next, you have to look at your product and ask yourself these three questions:
1. Can you actually break down usage into units?
What you’re going to be billing needs to relate directly with the value your customers are getting from your product. If you’re MailChimp you charge for sending emails and give templates away for free. Paying more money to send more emails makes sense to their customers.
Time can be a unit. If you’re AWS or Google you charge your customers based on the time they spend running their services on your hardware (plus many other things).
2. Can customers easily predict their usage requirements?
While customers want flexibility, they also hate unpredictable bills. This is why there is an interesting trend in enterprise software: multi-year contracts growing from 23% to 38% of agreements. They aren’t doing this for discounts, they’re locking in predictability, especially if AI-powered features are involved.
3. Are the usage and value of your products/services increasing?
If your customers are getting more value the more they use your tool, UBP allows your revenue to scale with their success.
Finally, consider your product. Do you need to develop entirely new features or services around your current offerings to make usage-based pricing make sense or are you ready to go?
How Do You Structure Usage-Based Pricing?
If you decide to move forward on UBP, you need to choose the right pricing structure. There are four primary variations to consider:
Variable Pricing: This model is based entirely on consumption. The most common example today is token-based pricing for AI models, but it could also apply to the number of reports generated, resolved customer support complaints (a model used by Intercom), or fraud predictions. This is typically managed via a credit-based system. Customers are given a default monthly credit allowance to help smooth out your revenue fluctuations, and they can buy more credits as their consumption increases. This is how platforms like Lovable handle their billing.
Tiered Pricing: Under this model, different unit costs apply as usage passes specific thresholds. Tiered pricing allows customers to maintain control over their budgets while ensuring your margins remain positive. It also lets you offer volume discounts to your largest accounts. The downside is that too many tiers confuse buyers, while too few make the price jump between tiers painful.
Dynamic Pricing: In this structure, prices shift in real time based on market conditions and demand. Uber’s surge pricing is the most familiar example of this model.
Per-Feature Pricing: Similar to variable pricing, this model charges customers only for the specific features they activate and use, often tracked via a credit-based system. This gives your customers complete autonomy over their costs, allowing them to balance the price-to-value equation themselves.
How Do You Deliver Usage-Based Pricing?
Building the technical infrastructure to support usage-based pricing is a significant engineering challenge. You will face three distinct hurdles: metering, storing, and implementation.
1. Metering
You must record consumption data exactly where it happens, whether that is API requests, token counts, or raw compute time. The recommended approach is “fire-and-forget”: your application code should emit a single billable event to your metering system the moment a transaction occurs.
For continuous workloads, like long-running background jobs or continuous compute, tracking start and end events is risky because data can be lost if a system crashes mid-job. Instead, use a “heartbeat” approach, where the active workload sends a heartbeat record to the metering system at regular intervals.
2. Storing and Processing
This is where you enter the world of data warehousing and complex stream processing. To provide real-time billing updates, you cannot simply dump records into a database and run batch jobs overnight; that leads to stale data. Most modern platforms rely on Kafka-based streaming architectures to process usage events in real time.
This data must be auditable. You cannot do this by halves, accuracy is paramount. If you are sharing revenue with partners or dealing with billing disputes, you need an audit trail that captures and tracks every single billable event.
Also, don’t treat usage data purely as an input for invoices. Your sales, product, customer success, and finance teams can all use access to this data. Real-time usage patterns can help sales spot upsell opportunities, help product teams track feature adoption, and help customer success flag accounts where dropping usage signals a risk of churn.
If you’re already tracking usage data for these purposes then lucky you, you’re already part way there.
3. Implementation
You do not have to build all of this billing infrastructure from scratch. There are lots of service providers out there already. You just need to instrument your code with those “fire-and-forget” messages to hit their databases and they give all the other tooling you need.
Here’s 3 examples:
Moesif: This platform specializes in metered API billing. It connects directly to API gateways like Kong or Tyk and integrates with payment processors to automate usage tracking and billing.
Stripe: In addition to standard subscription billing, Stripe supports complex usage catalogs (including models used by companies like Anthropic. They also offer an LLM proxy endpoint (in private preview), which automatically tracks token usage, applies your pricing markup, and handles invoicing in a single request.
Chargebee: offers usage-based billing features designed to separate your raw usage data from your pricing logic, making it easy to run experiments and iterate on your pricing tiers.
What to Watch Out For When Moving to Usage-Based Pricing
While the benefits of UBP are clear, the transition introduces real business risks that you need to manage.
The biggest challenge is revenue fluctuation. Unlike flat-rate subscriptions, your MRR will go up and down. To mitigate this, most companies use a hybrid pricing model. For example, you might charge a base subscription of $20 per month that includes 1,000 credits, and then charge a variable rate for extra credit purchases.
Another major risk occurs when you bill for consumption in arrears (charging after the usage has occurred, similar to AWS or Google Cloud). If an AI agent or a poorly written loop in a client’s code runs out of control, it can burn through thousands of dollars of spend. This leads to “bill shock,” which can ruin customer relationships or even bankrupt a small client.
Finally, remember that you are exposed to broader economic conditions. If your customers experience a business slowdown, their software usage—and your revenue—will drop alongside theirs. You may also face higher delinquency rates during market downturns.
Keep in Mind: Your Customers are Still Human
Even if AI agents are driving the usage, the person signing the contract and paying the bill is still a human. Humans require transparency, predictability, and clear communication. If you transition to usage-based billing, you must provide your customers with the tools, dashboards, and real-time alerts they need to monitor and manage their own consumption.
AI agents are changing how SaaS are run and valued. The traditional seat-based model is on its way out. While building the infrastructure to support usage-based billing is complex, we should be relieved we have a challenge that is straightforwardly solvable.
The alternative, in a world where people talk about using AI to build inhouse versions of the services they pay for, is not having a business at all.
Agile in the Age of AIAgile is how software is built. Its conceptualisation, its practices, its strategies have permeated software development, even in teams who are not Agile practitioners.
The determination of Agile was to keep the developers of software aligned with the users of the software. Alignment was maintained through feedback loops, sync points with the stakeholders, and the feedback loops were short: software was built incrementally and iteratively, and those increments were kept small so iteration could happen quickly and developers and stakeholders could never drift too far out of sync. This is what the Agile product stories and sprints grew out of, and technical practices like CI/CD developed to support them.
Now AI has broken Agile. Coding assistants and agents have changed the flow of software development: where time is spent, where costs are generated, where the sync points are.
We’re going to take a quick look at what AI is doing to Agile and what can be done to get the best of both tools. Rather than swapping between AI assistant, AI agent, coding agent, etc, we’re just going to call it AI.
How AI breaks Agile
Getting humans to iterate on code is expensive, so you want to get it right. You want your developers building the right pieces. This is why user stories, sprint planning, standups, ticket grooming and so on exist. It’s all done to reduce risk; the risk that your developers just spent weeks on the wrong code.
Getting AI to iterate on code is cheap and fast compared to getting humans to do it. It becomes the cheapest and fastest part of the process. A two week sprint can be completed in an hour or two. This changes project cadence, and project scheduling, and messes with the stakeholder sync points.
Do you have meetings every few hours to discuss the new feature implementation? Do you discuss forty new features at the next stakeholder meeting? What do you cover in your stand-ups?
AI shifts effort from coding to reviewing. Except the review schedule has been decoupled from human effort and timing. It is quite easy to instruct a few agents that go on to generate a constant flow of PRs, with each PR encompassing thousands of lines of changes across hundreds of files.
Review fatigue is real and results in developers skimming a fraction of the changes in a PR before accepting it. And they are going to accept it because they have been accepting PRs for weeks and their knowledge of the codebase is stale and getting back up to speed plus doing a proper review of the PR would take just as long as implementing the changes themselves.
The consequence of review fatigue is technical debt. Without pushback on its output, AI accumulates poorly architected code on top of poorly architected code. Eventually, an error occurs that overwhelms the context and the understanding of the AI. Slop can’t fix slop, as they say. And developers need to go back in and spend a schedule-breaking amount of time and effort to understand the codebase and implement fixes manually.
Making AI work with Agile
You can make AI work with Agile. You can tweak the methodology, you can use adopt new tools, and apply some old-fashioned discipline.
The first step in tweaking the methodology is to rethink your sync points with stakeholders. What should the unit of work look like? When does it make sense to meet and review progress?
And your sync points will depend on how you define when a unit of work is done. What does done look like when AI is generating your code?
Done should be when all tests pass and all metrics are met. All the tests and all the metrics. Because AI is trained to pass tests to the exclusion of all else (that is Reinforcement Learning in a nutshell – learning to pass tests), it can’t be trusted in how it passes tests. It will take shortcuts, it will try to shift the bar it is supposed to be clearing. This means that for every metric you need a secondary metric that detects cheating.
Your code test coverage needs to be paired with mutation testing. Performance benchmarks need to be paired with realistic data fixtures so you’re not surprised when customers start hammering your product. Find a counter-test for every test.
And once the tests pass and the metrics are met, then you still need to have humans do the review. This will be the cap on the unit of work and the limit on your throughput. It is an old fashioned “stitch in time saves nine” solution and one that should be bypassed only very grudgingly and only by deep testing and constant review (see, it’s inescapable) of the tools and processes you replace it with. And let’s admit it, the tools and processes you replace humans reviewing AI code with will always be AI reviewers of AI code.
Finally, consider what you’re going to cover in your daily scrums. Instead of individual status updates you want to be covering what reviewing needs to be done, what testing strategies are being put in place, what holes are showing up in your process that need patching.
This is a shift from building the product to managing the building of the product. And that shift is for everyone. Your developers will still write code, just much less. They will be managers of agents and monitors and arbiters of their agents’ outputs. AI flattens the workflow to two steps: Design → QA.
There is no conclusion to this
This is just a single step forward in what is a time of rapid constant change. While it does appear that AI abilities are plateauing, the software development industry is still evolving rapidly in its use of AI.
What is clear is that AI is not a super genius. It’s decisions can’t be relied on and its code cannot be trusted and we must verify, verify, verify. But sometimes we can use tools to handle that verification, and sometimes we can even use more AI.
And this is impacting where software developers spend their time, and where the bottlenecks are in building software products. It is an ongoing challenge to find the new best practices for the Agile development of software in the age of AI. We hope this gives you some ideas on where you can look to improve and optimise your practices.
The AI Job Replacement Calculator
(See Hardware for details)
| Rack | GB200 NVL72 | 36 Grace CPUs + 72 Blackwell GPUs, liquid-cooled |
| GPUs per rack | 72 × B200 | |
| Serving nodes | 9 × 8-GPU | 8-GPU tensor-parallel group |
| IT power | 120 kW | 115 kW liquid + 5 kW air |
| PUE | 1.2 | Modern liquid-cooled facility |
| Facility power | 144 kW | 120 × 1.2 |
| Racks per GW | 6,944 | 1,000,000 ÷ 144 |
- Token speeds — API-measured from Artificial Analysis (April 2026). May differ from bare-metal GB200 throughput.
- Kimi K2.6: 154.6 tok/s — AA (Clarifai). 1T/32B MoE
- Gemini 3.1 Pro: 112.2 tok/s — AA (Google API)
- GPT-5.5: 81.9 tok/s — AA (OpenAI, high)
- Claude Sonnet 4: 67.6 tok/s — AA (Anthropic API)
- Claude Opus 4: 47.7 tok/s — AA (Anthropic API)
- DeepSeek V4 Pro: 38.4 tok/s — AA (DeepSeek API)
- GB200 NVL72 — NVIDIA, The Register, DGX docs
- AI buildout — BloombergNEF: 23.1 GW under construction globally (Sept 2025). US: 15.9 GW, EMEA: 2.9 GW, APAC: 3.2 GW
- Buildout estimates — JLL: 103 GW → 200 GW by 2030 (~19 GW/yr). IEA: ~18–20 GW/yr implied. Sightline Climate: ~36% slippage rate → 10–15 GW/yr actual completions
- 300M jobs at risk — Goldman Sachs (2023): generative AI could expose ~300M full-time jobs globally to automation
It might be actual industry interest, or it might be the buying power of two corporate juggernauts’ marketing machines, but the new Starbucks app within OpenAI’s ChatGPT that let’s you create a coffee based on “vibes” is generating a lot of media.
For you, the interest is that the Starbuck’s app is an MCP App that’s letting their customers access their products from inside the UI that more and more people are spending more and more time in. When in Rome…
We’re going to give you a quick overview of MCP Apps and help you decide if you should build one.
What are MCP Apps and where did they come from
MCP is Model Context Protocol. It’s a standard announced, and open sourced, by Anthropic in November 2024 that provides a way to give AI access to APIs. It provides detailed description of what API endpoints do and expected data and return types. This is enough information for AI agents to understand how to request data, and the necessary information for the agent harness (ChatGPT, Claude Code, Cursor, Copilot, etc) to pass the data back and forth between the API and the agent.
MCP was an instant hit. Now you could connect AI to anything – databases, Stripe payments, coffee machines… Best practices in security and management followed and with the addition of proper authentication and permissioning, it has been embraced by enterprise. It provides the perfect interface for giving employees secure and monitored access to inhouse resources through the ubiquitous ChatGPT/Claude clients.
In October 2025 OpenAI announced their OpenAI Apps SDK. It was MCP with added on UI. That UI is built and rendered like ordinary web content, and so can provide users with any kind of interface and feature you’d like.
In November 2025, the App extension to MCP was launched as a provisional addition to the standard. This wasn’t a competing standard. It was heavily aligned with OpenAI’s Apps SDK, and in January this year it became a part of the Model Context Protocol.
OpenAI’s App SDK still has its own proprietary elements. OpenAI App SDK let’s your MCP App access local files, trigger checkout flows and use a bunch of other ChatGPT specific APIs.
It is interesting that despite OpenAI’s App SDK providing checkout flows, Starbuck’s MCP App opens their own website (or app if on a phone) to actually complete the order. This might be to avoid the inevitable fees going through OpenAI’s payment gateway incurs. We can only wonder if this option will remain available or if they will pull an Apple require all payments to go through their gateway so they can take their cut.
How MCP Apps work in a nutshell
MCP Apps rely on the harness. Whether it is ChatGPT, Claude, Claude Code, Copilot, etc, etc. The harness is the middleman between everyone:
User ↔ Harness ↔ Agent
MCP App widget ↔ Harness ↔ Agent
MCP App widget ↔ Harness ↔ User
MCP server ↔ Harness ↔ Agent
MCP server ↔ Harness ↔ Widget
This is to ensure that MCP Apps are safe to use. The UI itself runs in a sandboxed iframe. It can only talk to the outside world, including the server that delivered it to the harness, via the harness. If it wants to load data, it calls a function in the harness. If it wants to provide the agent with fresh information for its context, it calls a function in the harness.
Microsoft has some good examples of MCP Apps with complex UIs that allow the user to navigate information manually, while also asking the agent to take actions on the data.
The user can explore with the UI. The UI can send updates to the agent. The user can ask the agent to take actions based on what is happening in the UI. And if the MCP App provides the right tools, the agent can carry out actions that are reflected in the UI.
What an MCP App can do is limited by what tools (ie API access points) and data you expose to them.
Do you need to build an MCP App?
That depends on your users and your product. Are your users heavy users of AI? Have you checked?
Is your product part of a broader process or workflow? Is it a “mission control” style system?
Does your product generate data of any kind that needs to be communicated outside of your product? Do you already have some export functionality?
Then your users might appreciate an MCP App.
How to build an MVP MCP App yourself
The MCP group have all the documentation you need to build an MCP App. And they recommend you start by installing a skill in your AI coding agent and asking it to build it for you.
Of course, you need to give some thought and planning to authentication and permissions and payments and all the other complexities that make a product viable on top of how you are going to implement your UI.
You probably already have a UI. Can you retarget it to the MCP App interface easily?
Welcome to the next and possibly last API
One of the major shifts in building web-based products was the separation of apps into APIs and UIs. It meant your backend could drive an Android App as well as a website. Or an iPhone App. Or an AppleTV app.
MCP Apps are the next target for your APIs. And given the way AI is eating software the way software was supposed to eat the world, it might be the last target. At least the last target you need to write yourself.
Open Source Exploits And How To Protect Your Codebase From ThemOpen source software has become the foundation that the Internet and contemporary software – from phone apps to SaaS – is built on. It’s a vast library of code created and maintained, mostly, by volunteers. It’s the world of software development’s greatest asset, and it is becoming its greatest risk.
Popular open source libraries can be used in millions of projects, even without the project owner’s knowledge. Open source libraries are built on open source libraries, which are often built on open source libraries. There’s a chain of dependency, and if any link is compromised, the attackers win.
What the attackers win is generally access to cryptocurrency, if you have any. It seems to be the motivating factor for lots of exploits, going by the payloads they install. But stealing credentials and taking over accounts to enable ransom bids on businesses is also on the cards.
We’re going to look at the two most recent open source exploits and how they were accomplished. Then we’ll give you the basic advice for staying safe while still being able to participate in and reap the advantages of open source software.
Axios – don’t underestimate attackers’ resourcefulness
Axios is one of those foundational libraries that everyone uses because it simplifies common operations. Axios makes pulling data into browsers from servers more pleasant. It is part of the Node ecosystem, which means its part of the modern Javascript/React/SaaS world. It’s used everywhere.
This exploit was performed through social engineering. The attackers cloned a real company – including deep fakes of individuals for video calls and a Slack workspace with channels containing chatter and links to LinkedIn posts. On March 30 this year they invited the maintainer in, then started a video call. The video call webpage announced it needed an update installed. And the maintainer allowed the update to run.
But it wasn’t an update. It was a RAT – a Remote Access Trojan. It grabbed his credentials and updated the Axios repository to include a new dependency – a third party library the attackers had developed and uploaded to the npmjs package repository, where every client of the Axios library would be able to download it.
The attackers’ library ran a script that downloaded another RAT to every machine that updated their Axios installation. This gave the attackers remote access and total control over those machines.
LiteLLM – popularity leads to massive side effects
LiteLLM’s exploit was the result of an earlier successful exploit against Trivy, ironically a security scanner.
LiteLLM is a Python package rather than a Node package, and credentials accessed as a result of the Trivy compromise allowed attackers to access LiteLLM’s software publishing pipeline. This allowed them to add a credential stealer to the codebase on March 24 that would launch every time the library was accessed. The credential stealer grabbed everything from remote machine logins to cryptowallets.
LiteLLM makes it easy to connect to hundreds of AI models and providers. It is downloaded 3.4 million times a day (note – the bulk of these are automated downloads as part of testing and building software that uses LiteLLM). During the 46 minute period the exploit was live there were 46,996 downloads of the compromised software.
The exploit was found because it had a bug that resulted in any machine that downloaded it grinding to a halt within seconds. But there were still real consequences:
“AI hiring startup Mercor confirmed it was ‘one of thousands of companies’ affected by the LiteLLM supply-chain attack as the fallout from the Trivy compromise continues to spread. … The company’s admission follows claims by extortion crew Lapsus$ … that it stole 4 TB, including 939 GB of Mercor source code, plus other data, from the AI recruiting firm, and offered to sell the purloined files to the highest bidder.” — The Register, 2026-04-02
Strategies for staying safe while using open source libraries
While there are bad elements out there working to take advantage of open source, they are outnumbered by the people working to make open source safer. The open source world is going through a transition period at the moment, mostly driven by AI changing what can be accomplished with software and how fast. But this works just as well for defense as it does for attack. Scanning for exploits and more secure practices for package sites is coming online.
In the meantime, while dedicated teams are working at detecting and blocking exploits as quickly as possible,there are basic steps you can take that will greatly reduce your exposure.
- Add a mandatory “cooldown” period before new releases can be downloaded.Most exploits are found within minutes or hours. Waiting 3 days after a new release will give the security infrastructure time to discover any issues. Many package managers (like uv and pnpm) allow you to set that as a config option.
- Pin third party libraries by exact version (or commit SHA), and commit your lockfile. Don’t let your project simply move forward to the latest release.
- If the library is stable consider moving it from being an external dependency to an internal dependency by integrating it into your codebase. This is a move that coding agents make easier. If the “stable” library ever does see substantial changes, adding them to your codebase can be as simple as prompting your coding agent to do the work.
- Disable lifecycle/post-install scripts in your Continuous Integration. The Axios exploit relied on the library’s post-install script to do its work.
We’re living in interesting software times
Software has never been easier to bring into existence. Sadly, this includes exploits as well as beneficial tools. Open source software is and will remain an essential resource for every software developer out there. This is why individuals and organisations are pouring resources and ingenuity into keeping it secure and safe, and they have the numbers on their side.
Even with the speed and power of AI coding agents no-one can expect to build and maintain every piece of the software stack their business relies on. But by moving a little bit slower and setting some sensible defaults for how third party software is incorporated into your codebase, you can reduce your risk to the minimum while still getting all the benefits participating in the open source ecosystem brings.
The Three Trends Shaping the Future of AIWhen you look at how the frontier AI companies are talking and operating, the future looks like it will be filled with giant data centres within which all jobs are performed. It doesn’t appear to leave much for the rest of us.
Looking beyond OpenAI and Anthropic talking up their future prospects, there are some trends in software, hardware and AI that are bootstrapping off each other and pointing to a different direction things might go.
We’re going to look at these trends and show how they fit together and what it might mean, starting with software.
From Claude Code to Clawed Code
In May 2025 Claude Code became generally available. This agentic coding tool was one of the first tools to clearly demonstrate how capable models had become. Using the chat interface within a terminal (and the code open in an IDE), a developer could tell Claude to make some changes and then sit back and watch as the agent performed all the steps to find and read files, make edits and run tests. It might even do an online search if it needed more information.
The uptake of Claude Code was rapid, and subscriptions to it drove up Anthropic’s revenues. A whole new product category had been born. And it was a category that people were happy to pay for – unlike AI chat. Other model providers – Google, OpenAI – took notice and launched their own versions.
Anthropic continued to refine their models, training them to perform more consistently and diligently within the Claude Code “harness” and across the kinds of tasks developers needed completed.
In October of the same year Peter Steinberger, was working on a tool to connect Claude Code to a WhatsApp chat so he could keep working from his phone when he was away from his computer. It was simple middleman that ran commands from a WhatsApp chat in Claude Code and passed the results back to the chat.
Steinberger “discovered” that the Claude Code instance running back at home on his computer could use any command line tools it had available, and would even download and install tools if it needed them.
All the training Anthropic had performed to improve the coding workflow ability of the model had made it usable as a general agent.
Steinberger went on to build tools so Claude Code could access Google services, including mail and calendars, and the first “ClawdBot” was born. Three months later it was the fastest growing open source project in history, renamed to OpenClaw to avoid litigation, and Steinberger was hired by OpenAI.
Another new product category had been stumbled upon. And this one was not limited to developers. Ignoring all the security issues, people were using OpenClaw to run their businesses. People were installing OpenClaw for their parents. In China tech firms were having OpenClaw days where they helped consumers install it and get it connected to their services. OpenClaw as user lock-in.
Agents were no longer just for coders, they were for anyone. Agents were becoming the universal voice/chat interface to the complexities and drudgeries of the services everyone is forced to use.
Smarter, faster, smaller
Once a model is released, the providers continue to train them to improve performance. Training data is cumulative. The more training data you can collect over time (especially via free products where training on interactions is the price of using it) the more high quality data you can accumulate. Model providers have been collecting data from millions of users for a few years now.
At the same time, optimisation of model training is a global research focus in the field. As the data curation improves so do the techniques to make use of that data. The effects of this can be seen in the leap of ability in Claude Opus in late November 2025 and OpenAI’s GPT-5.2 a few weeks later. Developers reported both as the latest step change in model ability.
Post-training techniques and data curation are also benefitting open source models. These models are now only 3 to 6 months behind frontier models in performance and the intelligence gap between them has dropped to 5-7% according to the Artificial Analysis Intelligence Index.
Optimised training and curated data is resulting in small models that can be run on local hardware, like the Qwen3.5 9 Billion parameter model (released March 2026) that can beat GPT-4 on instruction following and reasoning.
The GPT-4-0613 model, though official numbers have never been released, was estimated to be a 1.7 Trillion parameter MOE model with 220 Billion parameters active at any one time. 200x larger than Qwen3.5 9B.
Qwen3.5 also comes in 27B, 35B-A3B, 122B-A10B, 397B-A17B sizes, as well as smaller 0.8B, 2B, 4B parameter versions.
The 27B model is smarter than the MOE 35B-A3B, but the MOE model, due to having only 3 billion parameters active at a time, can be used in lower memory environments and respond faster.
There has also been a shift towards 4 bit parameters, both on the training side (via Nvidia NVPF4) and on the local model side (eg Unsloth’s Qwen3.5 4 bit quants). Normally model parameters are a 16 bit floating point number (eg 0.29847). This means a 9 billion parameter model would need 18 gigabytes (16 bits = 2 bytes, 2 * 9B = 18B) just to be loaded into memory. Quantised to 4 bits in a way that minimises loss of quality, it can be loaded into 4GB of RAM.
The take away is that there exists smart, useful models that can match the resources available for compute.
Building brains for AI
In 2017 Apple announced the A11 Bionic chip for the new iPhoneX. It was a system-on-a-chip (SoC) that featured integrated CPU, memory, GPU, and a Neural Processing Unit (NPU). The NPU was used to power Face ID, computation photography (needed by the tiny camera), speech recognition and more.
Apple’s drive to bring more compute to the power-constrained environments of the iPhone and iPad translated nicely to their volume-constrained and slightly less power-constrained laptops. In November 2020 they launched the M1 – a laptop SoC that set new benchmarks in speed and efficiency, but was still just a higher-powered version of the chip powering the iPhone.
But in building a SoC that could support the iPhone’s best-in-class features, Apple ended up with an architecture that looks like it was designed for the AI boom. The memory tightly integrated with the processor instead of connected via copper traces running across circuit boards, the GPU and NPU cores – it all made running local AI models fast and efficient.
And because the memory architecture did not separate main memory from the memory available to the GPU and NPU, it meant M-series chips could run any model that could fit into the total memory available – up to 512GB on M3 Ultra chips.
Videos of developers running trillion parameter models on Apple hardware (Kimi K2.5 on M3 Ultra Mac Studios) made developers on PCs with 16 GB GPU cards take notice. So did CPU manufacturers. They have all started bringing out their own SoCs targeting local AI:
- AMD Ryzen AI Max
- Intel Lunar Lake
- NVIDIA DGX Spark
- Qualcomm Snapdragon X Elite
- MediaTek Kompanio Ultra
This move from designing and building general purpose CPUs to AI-optimised SoCs is a seismic shift in the marketplace. It’s bigger than PCs arriving with graphics capabilities or WiFi.
Nvidia is still a great believer in the RTX AI PC, which is simply the current PC+GPU set up. These are step up in performance but come at a price, and that price currently limits the size of models that can be run on them.
Where these trends might lead
Over the next few years, between hardware improvements and model intelligence increasing, most people’s needs for any kind of AI agent will be able to be met by a model running locally on their own machine.
Most people don’t build front ends for websites. They don’t need frontier coding models. And the people who do build front ends for websites: they have all the same administrative, scheduling and service navigation needs everyone else does.
Agents, the product that OpenAI, Anthropic and Nvidia want to sell to enterprise and everyone else; and what we expect is the start of general AI usage spreading out into the world, will not be able to be kept locked behind a paywall.
While the giant data centres look like a bid to corner the supply of compute, and thus control the price of access to AI (not at all helped by Sam Altman stockpiling RAM), trends in small local model intelligence and improvements in the hardware they run on suggest choice and control might remain in the hands of individual users and businesses.